简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。Hadoop的运行模式分为三种:单机模式、伪分布式模式、完全分布式模式。
- 单机模式(Local (Standalone) Model)
Hadoop的默认模式,0配置。Hadoop运行在一个Java进程中,使用本地文件系统,不使用HDFS,一般用于开发调试MapReduce程序的应用逻辑。
- 伪分布式模式(Pseudo-Distributed Model)
需简单配置,相当于只有一个节点的集群,Hadoop的所有守护进程运行在同一台机器上。该模式在单机模式之上增加了代码调试功能,允许你检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。
- 完全分布式模式(Fully-Distributed Model)
根据需要进行配置。多节点,一般用于生产环境,可认为是由伪分布式模式的一个节点变为多个节点。
Hadoop 搭建与管理
搭建Hadoop环境需要的生态环境及工具:Linux系统环境、JDK安装及其环境变量、ssh及ssh的免密码登录、Hadoop安装包、环境变量的配置。
系统环境
使用系统环境为:Linux CentOS 7
[root@localhost ~]# uname -a
Linux node 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
[root@localhost ~]# Java环境
删除系统自带的openjdk(openjdk是jdk的精简版),然后安装使用jdk-8u231-linux-x64
(1)先卸载openjdk
[root@localhost ~]# rpm -qa|grep java
javapackages-tools-3.4.1-11.el7.noarch
tzdata-java-2018e-3.el7.noarch
java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64
java-1.7.0-openjdk-1.7.0.191-2.6.15.5.el7.x86_64
python-javapackages-3.4.1-11.el7.noarch
java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.191-2.6.15.5.el7.x86_64
[root@localhost ~]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.181-7.b13.el7.x86_64
[root@localhost ~]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
[root@localhost ~]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.191-2.6.15.5.el7.x86_64
[root@localhost ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.191-2.6.15.5.el7.x86_64
[root@localhost ~]# rpm -qa|grep java
javapackages-tools-3.4.1-11.el7.noarch
tzdata-java-2018e-3.el7.noarch
python-javapackages-3.4.1-11.el7.noarch
[root@localhost ~]#(2)安装jdk-8u231-linux-x64 (自行去官网下载)
[root@localhost HadoopEnv]# tar -zxvf jdk-8u231-linux-x64.tar.gz
[root@localhost ~]# vim /etc/profile
#java
export JAVA_HOME=/root/HadoopEnv/jdk1.8.0_231
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
[root@localhost ~]# source /etc/profile
[root@localhost ~]# java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode)
[root@localhost ~]# 预配置环境
在配置主机Hadoop环境时,先给主机配置静态IP、主机名和IP映射,方便后续Hadoop的配置
(1)给主机配置静态IP
[root@localhost ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPADDR=192.33.6.191
NETMASK=255.255.255.0
GATEWAY=192.33.6.2
DNS1=8.8.8.8
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
DEVICE=ens33
ONBOOT=yes
[root@localhost ~]# (2)主机名与IP映射
- 设置主机名
[root@localhost ~]# hostnamectl set-hostname master
[root@localhost ~]# su -
上一次登录:四 6月 4 06:57:36 CDT 2020:0 上
[root@master ~]#- 设置IP映射
输入vim /etc/hosts添加本机的IP映射,修改之后文件如下:
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.33.6.191 master
[root@master ~]#单机模式
官网下载相应Hadoop版本(hadoop-2.8.5.tar.gz),解压到相应路径
[root@master HadoopEnv]# tar -zxvf hadoop-2.8.5.tar.gz- 配置profile文件
通过配置profile文件来配置Hadoop系统变量,执行vim /etc/profile,在profile下面加入:如下环境变量
#Hadoop
export HADOOP_HOME=/root/HadoopEnv/hadoop-2.8.5
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH设置后,执行source /etc/profile使文件修改生效
- 验证hadoop
[root@master HadoopEnv]# hadoop version输入命令,如果出现下面的信息,说明Hadoop安装成功
Hadoop 2.8.5
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8
Compiled by jdu on 2018-09-10T03:32Z
Compiled with protoc 2.5.0
From source with checksum 9942ca5c745417c14e318835f420733
This command was run using /root/HadoopEnv/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar- 实验单机环境
在所有准备工作完成后,单机模式部署已经完成,下面就实验一下
[root@master HadoopEnv]# mkdir testd
[root@master HadoopEnv]# cd testd/
[root@master testd]# mkdir input
[root@master testd]# echo "This is test." >> input/test
[root@master testd]# hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount input output
[root@master testd]# cat output/*上面就是Hadoop版的Hello World,如果成功打印下面信息:
This 1
is 1
test. 1说明所有环境已经准备好,可以调试程序或者进行Hadoop伪分布式模式部署了。
伪分布式模式
伪分布式模式的准备工作与单机模式相同,唯一需要做的改变是要修改Hadoop的部分配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。
环境搭建
进入目录$HADOOP_HOME/etc/hadoop/对相关配置文件进行配置
- 配置hadoop-env.sh文件
Hadoop运行在JDK之上,原本hadoop-env.sh文件中使用的是相对路径,但是在一些环境中会报错,因此此处修改为绝对路径。执行vim hadoop-env.sh,将 export JAVA_HOME=${JAVA_HOME}更改为export JAVA_HOME=/root/HadoopEnv/jdk1.8.0_231
- 配置core-site.xml文件
修改$HADOOP_HOME/etc/hadoop/core-site.xml文件。在默认情况下,这个文件为空,没有任何配置,这里需要指定NameNode的ip和端口
<configuration>
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/HadoopEnv/hadoop-2.8.5/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!-- fs.trash.interval是在指在这个回收周期之内,文件实际上是被移动到trash的这个目录下面,而不是马上把数据删除掉。等到回收周期真正到了以后,hdfs才会将数据真正删除。默认的单位是分钟,1440分钟=60*24,刚好是一天; -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<!-- fs.trash.checkpoint.interval则是指垃圾回收的检查间隔,应该是小于或者等于fs.trash.interval -->
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1440</value>
</property>
</configuration>PS1:Hadoop默认将HDFS文件系统写在/tmp/hadoop-中,因为系统重启会清理/tmp目录,所以需要保证重启系统不丢失数据,需要修改默认数据保存位置。
PS2:注意此处需要在命令行中新建相应的文件夹,执行mkdir $HADOOP_HOME/tmp
- 配置hdfs-site.xml文件
这个文件是NameNode的相关配置文件
HDFS是分布式文件系统,为了安全性考虑,会将上传至HDFS的文件的每个分块拷贝到N个节点上,即复制N次(这里的N成为复制因子)。这里将复制因子改为1。
<configuration>
<!-- 指定HDFS副本的数量 默认为3个-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///root/HadoopEnv/hadoop-2.8.5/hdfs/name</value>
</property>
<property>
<name>dfs.dataenode.data.dir</name>
<value>file:///root/HadoopEnv/hadoop-2.8.5/hdfs/data</value>
</property>
</configuration>PS1:Hadoop默认将HDFS文件系统写在/tmp/hadoop-中,因为系统重启会清理/tmp目录,所以需要保证重启系统不丢失数据,需要修改默认数据保存位置。
PS2:注意此处需要在命令行中新建相应的文件夹,分别执行:
mkdir -p $HADOOP_HOME/hdfs/name
mkdir -p $HADOOP_HOME/hdfs/data- 免密操作
[root@master ~]# ssh-keygen -t rsa
[root@master ~]# ssh-copy-id master测试免密操作
[root@master ~]# ssh master
Last login: Sat Jun 6 03:41:37 2020 from master
[root@master ~]#
[root@master ~]# exit
登出
Connection to master closed.
[root@master ~]#- 关闭防火墙
[root@master sbin]# systemctl stop firewalld
[root@master sbin]# systemctl disable firewalld启动最小Hadoop伪分布式模式
经过上面的最小配置后,Hadoop已经可以启动伪分布式模式了。
- 格式化文件系统
第一次运行Hadoop的时候需要格式化其文件系统:
[root@master HadoopEnv]# hadoop namenode -format如果成功,返回的信息包含如下一部分:
20/06/05 13:42:29 INFO common.Storage: Storage directory /root/HadoopEnv/hadoop-2.8.5/hdfs/name has been successfully formatted.或者在/root/HadoopEnv/hadoop-2.8.5/hdfs/name目录下有新的文件生成。
- 启动NameNode守护进程和DataNode守护进程
直接通过Hadoop提供的脚本start-dfs.sh即可:
[root@master HadoopEnv]# sbin/start-dfs.sh启动日志保存在$HADOOP_LOG_DIR目录中(默认是$HADOOP_HOME/logs)。
- 查看启动的进程
可以通过jps查看已经启动的进程:
31536 SecondaryNameNode
31381 DataNode
31254 NameNode
31643 Jps说明DataNode、NameNode、SecondaryNameNode已经启动成功。
- 查看NameNode的web接口
通过默认的NameNode的web接口http://localhost:50070/,可以查看NameNode收集的信息,相当于关于Hadoop提供的一个信息查询系统。
- Hello World
执行官网提供的验证程序
$ hdfs dfs -mkdir /input
$ hdfs dfs -put $HADOOP_HOME/etc/hadoop/* /input
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar grep /input /output 'dfs[a-z.]+'
$ hdfs dfs -cat /output/*最后一条命令是显示最后的执行结果:
6 dfs.audit.logger
4 dfs.class
3 dfs.server.namenode.
2 dfs.period
2 dfs.audit.log.maxfilesize
2 dfs.audit.log.maxbackupindex
1 dfsmetrics.log
1 dfsadmin
1 dfs.servers
1 dfs.replication
1 dfs.file- 停止进程
伪分布式模式中的第一个Hello World执行成功后,可以关闭进程了。
[root@master HadoopEnv]# stop-dfs.sh配置YARN
通过配置一些参数,并启动ResourceManager守护进程和NodeManager守护进程,可以在伪分布式模式中,在YARN上运行MapReduce任务。
上面的最小配置不变。
- 配置mapred-site.xml文件
这个文件是配置MapReduce任务的配置文件
在默认的Hadoop安装包中,没有mapred-site.xml文件,可以复制mapred-site.xml.template,并修改,指定在YARN中运行MapReduce任务:
cp mapred-site.xml.template mapred-site.xml编辑mapred-site.xml文件
<configuration>
<!-- 指定mr运行时框架,这里指定在yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>设置执行job的是Yarn框架</description>
</property>
</configuration>- 配置yarn-site.xml文件
这个文件是配置ResourceManager和NodeManager的配置文件
<configuration>
<!-- reduce获取数据的方式,指明需要向MapReduce应用提供的Shuffle服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>排序服务</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>- 运行
可以通过start-yarn.sh启动ResourceManager守护进程和NodeManager守护进程,通过stop-yarn.sh停止。
通过访问http://localhost:8088/可以到默认的MR管理界面。
完全分布式模式
完全分布式模式与伪分布式模式类似,只是有些许的不同,如下:
环境修建
- 环境
如下四台主机
192.33.6.191 master ---->>> NameNode ResourceManager JobHistoryServer
192.33.6.192 slave1 ---->>> DataNode NodeManager
192.33.6.193 slave2 ---->>> DataNode NodeManager
192.33.6.194 master2nd ---->>> SecondaryNameNode- 主机映射
由原来的一台变为四台或更多台
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.33.6.191 master
192.33.6.192 slave1
192.33.6.193 slave2
192.33.6.194 master2nd
[root@master ~]#- hadoop-env.sh文件
$ vim hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
替换
export JAVA_HOME=/root/HadoopEnv/jdk1.8.0_231- core-site.xml文件
<configuration>
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/HadoopEnv/hadoop-2.8.5/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!-- fs.trash.interval是在指在这个回收周期之内,文件实际上是被移动到trash的这个目录下面,而不是马上把数据删除掉。等到回收周期真正到了以后,hdfs才会将数据真正删除。默认的单位是分钟,1440分钟=60*24,刚好是一天; -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<!-- fs.trash.checkpoint.interval则是指垃圾回收的检查间隔,应该是小于或者等于fs.trash.interval -->
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1440</value>
</property>
</configuration>- hdfs-site.xml文件
更改HDFS副本的数量及增添其他配置
<configuration>
<!-- 指定HDFS副本的数量 默认为3个-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.rpc-address</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master2nd:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///root/HadoopEnv/hadoop-2.8.5/hdfs/name</value>
<description>NameNode在本地文件系统中存储命名空间和持久化日志的位置</description>
</property>
<property>
<name>dfs.dataenode.data.dir</name>
<value>file:///root/HadoopEnv/hadoop-2.8.5/hdfs/data</value>
<description>DataNode存储数据的位置,如果是用逗号隔开的多个路径,每个路径都存一份</description>
</property>
</configuration>- mapred-site.xml文件
新增对历史服务器的配置
<configuration>
<!-- 指定mr运行时框架,这里指定在yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>设置执行job的是Yarn框架</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<description>JobHistoryServer的URI</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<description>JobHistoryServer web服务的URI</description>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/root/HadoopEnv/hadoop-2.8.5/yarn/staging</value>
<description>job数据存储位置</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/root/HadoopEnv/hadoop-2.8.5/yarn/history/done_intermediate</value>
<description>job的历史数据的临时位置</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/root/HadoopEnv/hadoop-2.8.5/yarn/history/done</value>
<description>job的历史数据的归档位置</description>
</property>
</configuration>PS:注意此处需要在命令行中新建相应的文件夹,分别执行:
mkdir -p $HADOOP_HOME/yarn/staging
mkdir -p $HADOOP_HOME/yarn/history/done_intermediate
mkdir -p $HADOOP_HOME/yarn/history/done- yarn-site.xml文件
<configuration>
<!-- reduce获取数据的方式,指明需要向MapReduce应用提供的Shuffle服务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>排序服务</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>- 配置master文件
该文件需要自己创建,用于将NameNode与Secondary NameNode分别部署:
[root@master hadoop]# vim master
[root@master hadoop]# cat master
master2nd
[root@master hadoop]#- 配置slaves文件
修改slaves文件,指明从节点主机,默认是localhost
slave1
slave2- 免密操作
ssh必须安装,且sshd必须是运行状态,因为Hadoop调用远程进程使用sshd(在单机模式中这个不是必须的)。另外,需要实现master节点向slave节点的无密码登录。
[root@master ~]# ssh-keygen -t rsa
[root@master ~]# ssh-copy-id master
[root@master ~]# ssh-copy-id slave1
[root@master ~]# ssh-copy-id slave2
[root@master ~]# ssh-copy-id master2nd测试免密操作
[root@master ~]# ssh root@slave1
Last login: Sat Jun 6 01:33:03 2020
[root@slave1 ~]# exit
登出
Connection to slave1 closed.
[root@master ~]#
[root@master ~]# ssh root@slave2
Last login: Sat Jun 6 01:33:16 2020
[root@slave2 ~]# exit
登出
Connection to slave2 closed.
[root@master ~]#
or
[root@master ~]# ssh slave1
[root@master ~]# ssh slave2
[root@master ~]# ssh master
[root@master ~]# ssh master2nd- 关闭防火墙
[root@master sbin]# systemctl stop firewalld
[root@master sbin]# systemctl disable firewalld
[root@slave1 ~]# systemctl stop firewalld
[root@slave1 ~]# systemctl disable firewalld
[root@slave2 ~]# systemctl stop firewalld
[root@slave2 ~]# systemctl disable firewalld
[root@master2nd ~]# systemctl stop firewalld
[root@master2nd ~]# systemctl disable firewalld- 开启时钟同步
$ rpm -qa | grep ntp
开启时钟同步并设置自启
$ systemctl start ntpd
$ systemctl enable ntpd
在子节点上执行时钟同步命令
$ ntpdate master完全分布式
结合伪分布式模式配置完master主机后,使用scp命令将主节点上的jdk和hadoop环境及环境变量、IP映射拷贝到两个从节点主机上slave1与slave2上以及SecondaryNameNode主机上。
[root@master ~]# scp -r HadoopEnv/ slave1:/root/
[root@master ~]# scp -r HadoopEnv/ slave2:/root/
[root@master ~]# scp -r HadoopEnv/ master2nd:/root/
[root@master ~]# scp /etc/profile slave1:/etc/
[root@master ~]# scp /etc/profile slave2:/etc/
[root@master ~]# scp /etc/profile master2nd:/etc/
[root@master ~]# scp /etc/hosts slave1:/etc/
[root@master ~]# scp /etc/hosts slave2:/etc/
[root@master ~]# scp /etc/hosts master2nd:/etc/在从节点主机上使用source命令刷新环境配置文件/etc/profile
[root@slave1 ~]# source /etc/profile
[root@slave2 ~]# source /etc/profile
[root@master2nd ~]# source /etc/profile测试完全分布式
HDFS
- 启动HDFS
[root@master sbin]# start-dfs.sh
20/06/06 15:34:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [master]
master: starting namenode, logging to /root/HadoopEnv/hadoop-2.8.5/logs/hadoop-root-namenode-master.out
slave2: starting datanode, logging to /root/HadoopEnv/hadoop-2.8.5/logs/hadoop-root-datanode-slave2.out
slave1: starting datanode, logging to /root/HadoopEnv/hadoop-2.8.5/logs/hadoop-root-datanode-slave1.out
Starting secondary namenodes [master2nd]
master2nd: starting secondarynamenode, logging to /root/HadoopEnv/hadoop-2.8.5/logs/hadoop-root-secondarynamenode-master2nd.out
20/06/06 15:35:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@master sbin]#- 查看jps结果
[root@master sbin]# jps
8964 Jps
8665 NameNode
[root@master sbin]#
[root@slave1 ~]# jps
8114 DataNode
8180 Jps
[root@slave1 ~]#
[root@slave2 ~]# jps
8166 DataNode
8232 Jps
[root@slave2 ~]#
[root@master2nd ~]# jps
9273 Jps
9226 SecondaryNameNode
[root@master2nd ~]#YARN
- 启动YARN
[root@master sbin]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /root/HadoopEnv/hadoop-2.8.5/logs/yarn-root-resourcemanager-master.out
slave2: starting nodemanager, logging to /root/HadoopEnv/hadoop-2.8.5/logs/yarn-root-nodemanager-slave2.out
slave1: starting nodemanager, logging to /root/HadoopEnv/hadoop-2.8.5/logs/yarn-root-nodemanager-slave1.out
[root@master sbin]#- 查看jps结果
[root@master sbin]# jps
9014 ResourceManager
8665 NameNode
9277 Jps
[root@master sbin]#
[root@slave1 ~]# jps
8114 DataNode
8326 Jps
8216 NodeManager
[root@slave1 ~]#
[root@slave2 ~]# jps
8166 DataNode
8376 Jps
8267 NodeManager
[root@slave2 ~]#
[root@master2nd ~]# jps
9273 Jps
9226 SecondaryNameNode
[root@master2nd ~]#Hadoop服务
通过web接口查看相应Hadoop服务
- Namenode information
HDFS管理界面
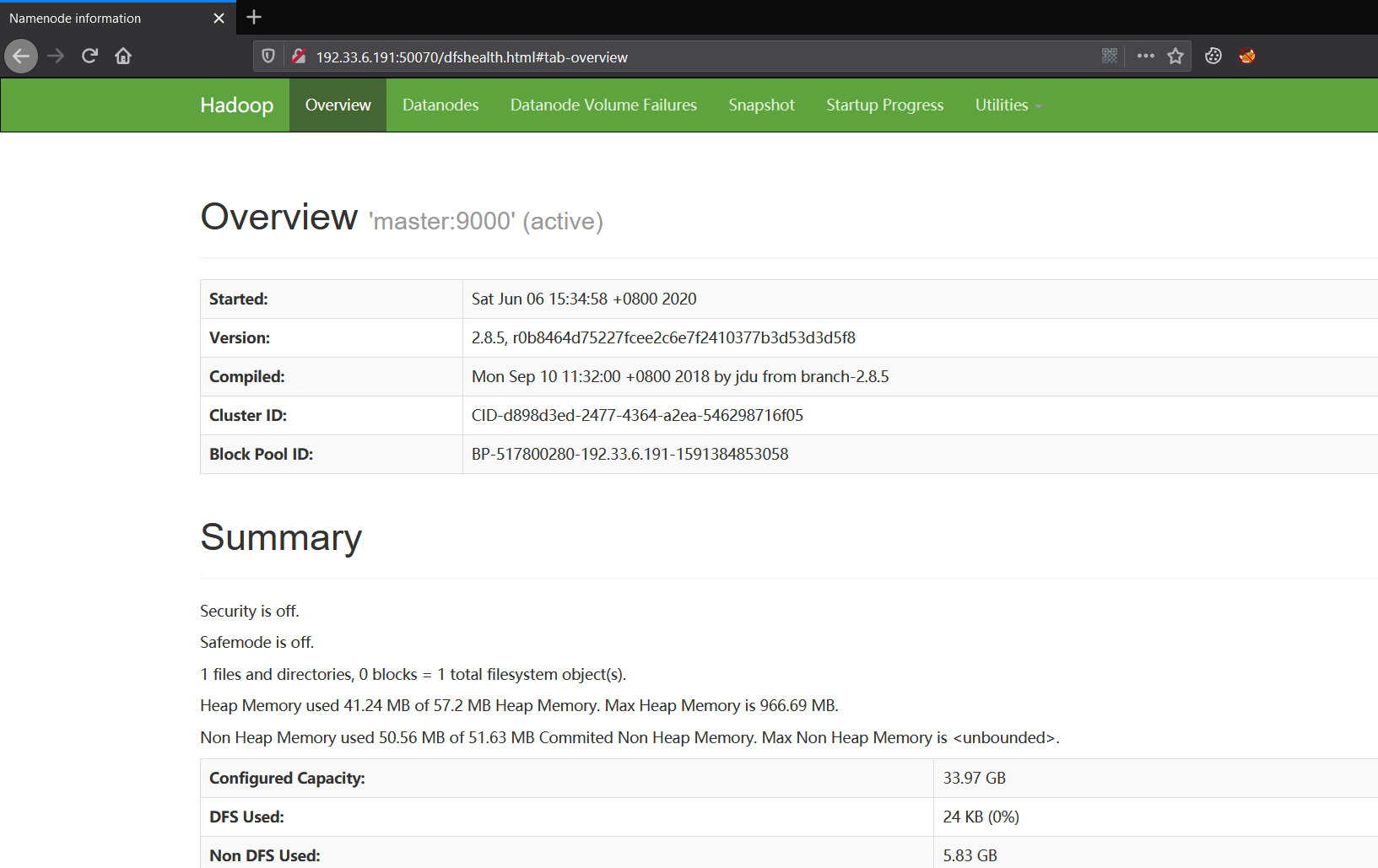
- SecondaryNamenode information

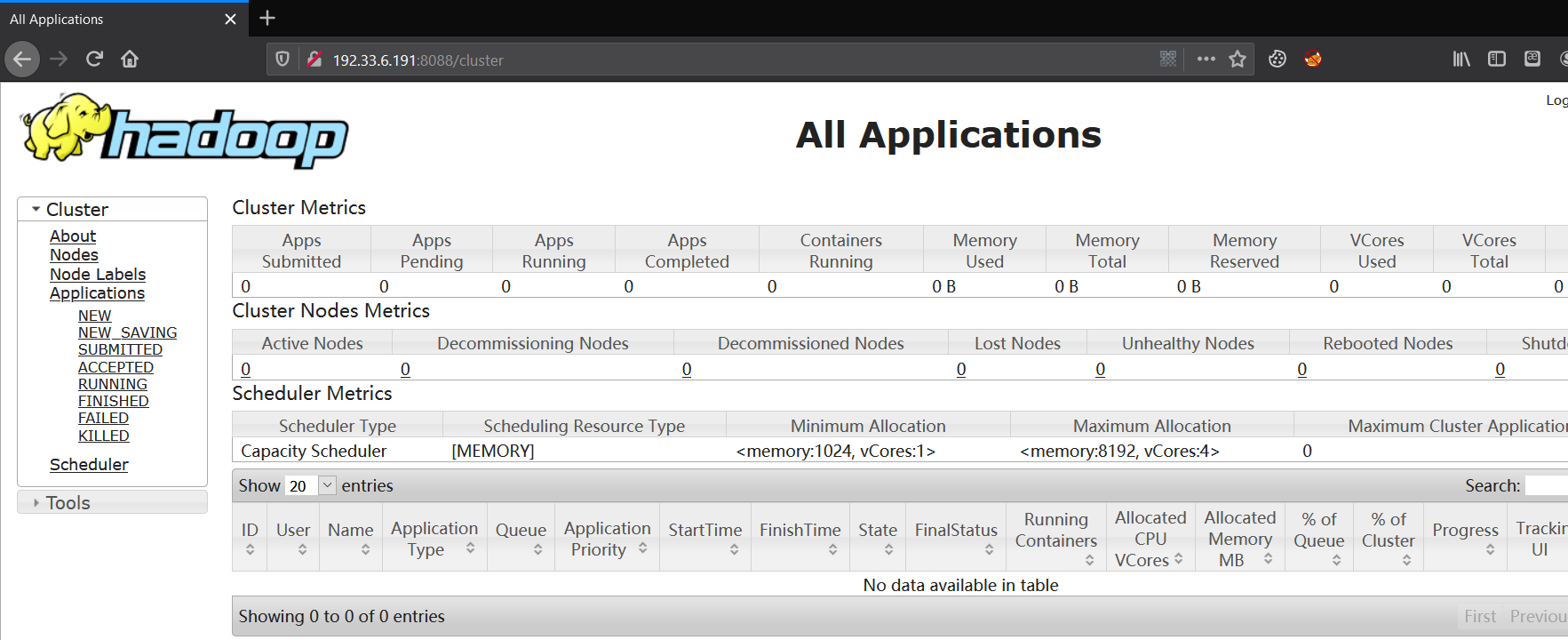
- All Applications
MR管理界面
- JobHistory
Hadoop Jobhistory记录下已运行完的MapReduce作业信息并存放在指定的HDFS目录下。
默认情况下该服务是没有启动的,需要配置完后手工启动服务(配置见上面:mapred-site.xml文件配置)。
[root@master sbin]# mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /root/HadoopEnv/hadoop-2.8.5/logs/mapred-root-historyserver-master.out
[root@master sbin]# jps
10353 NameNode
11080 JobHistoryServer
10633 ResourceManager
11117 Jps
[root@master sbin]#
[root@master sbin]# mr-jobhistory-daemon.sh stop historyserver
stopping historyserver
[root@master sbin]#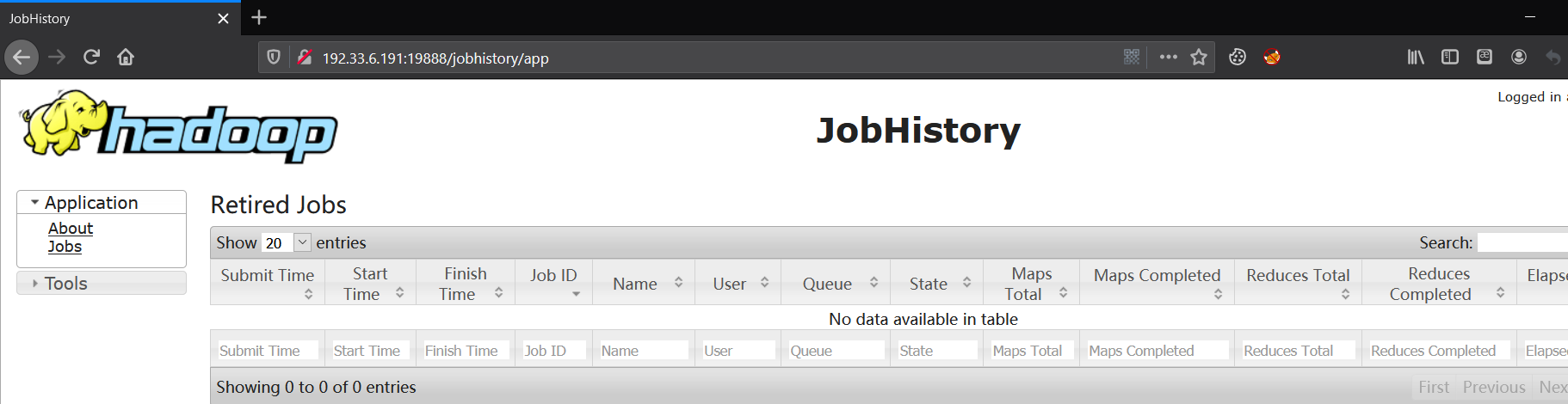
- 关闭Hadoop服务
[root@master sbin]# stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
20/06/06 15:54:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping namenodes on [master]
master: stopping namenode
slave2: stopping datanode
slave1: stopping datanode
Stopping secondary namenodes [master2nd]
master2nd: stopping secondarynamenode
20/06/06 15:54:45 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
stopping yarn daemons
stopping resourcemanager
slave2: stopping nodemanager
slave1: stopping nodemanager
slave2: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
slave1: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
no proxyserver to stop
[root@master sbin]# jps
11630 Jps
[root@master sbin]#分布式计算
HDFS上传文件core-site.xml
[root@master sbin]# hdfs dfs -lsr /input
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 2 root supergroup 1238 2020-06-07 19:16 /input/core-site.xml
[root@master sbin]#在集群下运行Hadoop自带的词频统计程序并查看执行结果
对core-site.xml文件进行计算统计
[root@master sbin]# hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /input/core-site.xml /output
20/06/07 23:42:31 INFO client.RMProxy: Connecting to ResourceManager at master/192.33.6.191:8032
20/06/07 23:42:33 INFO input.FileInputFormat: Total input files to process : 1
20/06/07 23:42:33 INFO mapreduce.JobSubmitter: number of splits:1
20/06/07 23:42:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1591544387638_0002
20/06/07 23:42:34 INFO impl.YarnClientImpl: Submitted application application_1591544387638_0002
20/06/07 23:42:34 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1591544387638_0002/
20/06/07 23:42:34 INFO mapreduce.Job: Running job: job_1591544387638_0002
20/06/07 23:42:49 INFO mapreduce.Job: Job job_1591544387638_0002 running in uber mode : false
20/06/07 23:42:49 INFO mapreduce.Job: map 0% reduce 0%
20/06/07 23:42:59 INFO mapreduce.Job: map 100% reduce 0%
20/06/07 23:43:07 INFO mapreduce.Job: map 100% reduce 100%
20/06/07 23:43:07 INFO mapreduce.Job: Job job_1591544387638_0002 completed successfully
20/06/07 23:43:08 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=1593
FILE: Number of bytes written=319427
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1341
HDFS: Number of bytes written=1219
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=7832
Total time spent by all reduces in occupied slots (ms)=5267
Total time spent by all map tasks (ms)=7832
Total time spent by all reduce tasks (ms)=5267
Total vcore-milliseconds taken by all map tasks=7832
Total vcore-milliseconds taken by all reduce tasks=5267
Total megabyte-milliseconds taken by all map tasks=8019968
Total megabyte-milliseconds taken by all reduce tasks=5393408
Map-Reduce Framework
Map input records=33
Map output records=120
Map output bytes=1670
Map output materialized bytes=1593
Input split bytes=103
Combine input records=120
Combine output records=92
Reduce input groups=92
Reduce shuffle bytes=1593
Reduce input records=92
Reduce output records=92
Spilled Records=184
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=210
CPU time spent (ms)=1580
Physical memory (bytes) snapshot=284033024
Virtual memory (bytes) snapshot=4161449984
Total committed heap usage (bytes)=134393856
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1238
File Output Format Counters
Bytes Written=1219
[root@master sbin]#查看output目录下计算统计的结果
[root@master sbin]# hdfs dfs -cat /output/*
"AS 1
"License"); 1
(the 1
--> 4
2.0 1
<!-- 4
</configuration> 1
</property> 2
<?xml 1
<?xml-stylesheet 1
<configuration> 1
<description>Abase 1
<name>fs.default.name</name> 1
<name>hadoop.tmp.dir</name> 1
<property> 2
<value>/root/HadoopEnv/hadoop-2.8.5/tmp</value> 1
<value>hdfs://master:9000</value> 1
ANY 1
Apache 1
BASIS, 1
CONDITIONS 1
IS" 1
KIND, 1
LICENSE 1
License 3
License, 1
License. 2
Licensed 1
OF 1
OR 1
Put 1
See 2
Unless 1
Version 1
WARRANTIES 1
WITHOUT 1
You 1
a 1
accompanying 1
agreed 1
an 1
and 1
applicable 1
at 1
by 1
compliance 1
copy 1
directories.</description> 1
distributed 2
either 1
encoding="UTF-8"?> 1
except 1
express 1
file 1
file. 2
for 2
governing 1
href="configuration.xsl"?> 1
http://www.apache.org/licenses/LICENSE-2.0 1
implied. 1
in 3
is 1
language 1
law 1
limitations 1
may 2
not 1
obtain 1
of 1
on 1
or 2
other 1
overrides 1
permissions 1
property 1
required 1
site-specific 1
software 1
specific 1
temporary 1
the 7
this 2
to 1
type="text/xsl" 1
under 3
use 1
version="1.0" 1
with 1
writing, 1
you 1
指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 1
指定hadoop运行时产生文件的存储目录,默认/tmp/hadoop-${user.name} 1
[root@master sbin]#通过访问MR管理器,查看对应job的Application信息
http://master:8088/cluster/app/application_1591544387638_0002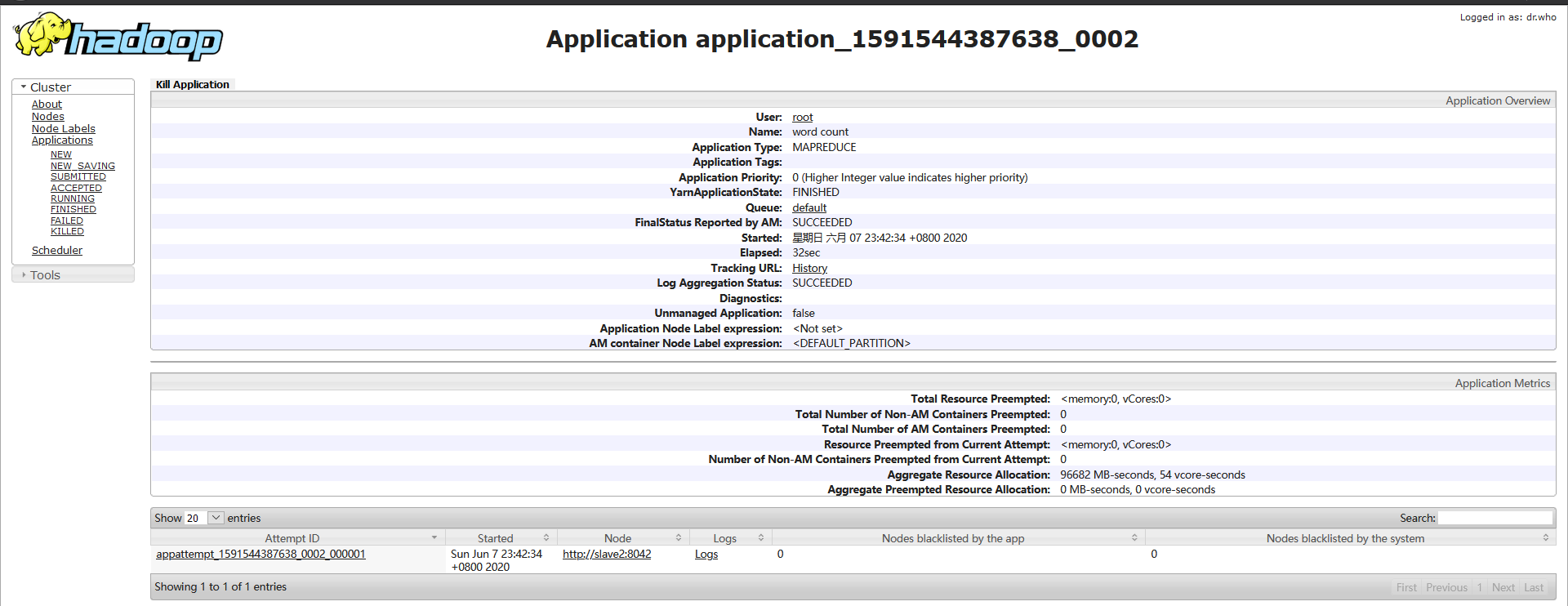
HDFS Shell 和 API 的使用
HDFS Shell
官方手册
命令区别
- hadoop fs、hadoop dfs与hdfs dfs的区别
hadoop fs:使用面最广,可以操作任何文件系统。
hadoop dfs与hdfs dfs:只能操作HDFS文件系统相关(包括与Local FS间的操作),前者已经Deprecated,一般使用后者。
命令查询
[root@master ~]# hdfs dfs --help
--help: Unknown command
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-x] <path> ...]
[-expunge]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
command [genericOptions] [commandOptions]
[root@master ~]#JAVA API
简介
Hadoop 2.8.5 Java API 官方地址:http://hadoop.apache.org/docs/r2.8.5/api/index.html
Hadoop集群提供HDFS的JAVA API接口,易于编程使程序对API接口进行一系列操作从而实现对HDFS的功能操作。
常用类
- configuration
此类封装了客户端或服务器的配置,通过配置文件来读取类路径实现(一般是core-site.xml)。
- FileSystem
一个通用的文件系统api,用该对象的一些方法来对文件进行操作。
注意:FileSystem的get()方法有两个
FileSystem fs = FileSystem.get(URI.create("hdfs://master:9000"),conf); //默认在hdfs上读取文件
FileSystem fs = FileSystem.get(conf); //默认从本地上读取文件- FSDataInputStream
HDFS的文件输入流,FileSystem.open()方法返回的即是此类。
- FSDataOutputStream
HDFS的文件输出流,FileSystem.create()方法返回的即是此类。
编程
编写Java程序远程操作HDFS API。
程序环境
客户端 Windows10
编译器 IDEA
JAVA JDK1.8
服务端 Linux Hadoop集群程序要求
编写Java程序在HDFS中创建文件和文件夹,再将文件下载到本地,并从本地上传多个新的文件到HDFS的某一目录下,然后进行遍历,查看文件相关信息。
程序编写
package com.hdfs.api;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ReadWrite {
public static void main(String[] args) throws Exception{
FileSystem fs=FileSystem.get(new URI("hdfs://master:9000"),new Configuration(),"root");
Path dfs1=new Path("/HdfsFile/fe.txt");
Path local=new Path("C:\\Users\\Qftm\\Desktop");
Path src=new Path("C:\\Users\\Qftm\\Desktop\\hdfs");
Path dst=new Path("/javaapi");
Path dfs2=new Path("/javaapi/hdfs/MysqlLoadFile.txt");
Path dfs3=new Path("/javaapi/hdfs");
FSDataOutputStream create = fs.create(dfs1);
fs.copyToLocalFile(dfs1, local);
System.out.println("download: from" + dfs1 + " to " + local);
fs.copyFromLocalFile(src, dst);
System.out.println("copy from: " + src + " to " + dst);
FileStatus filestatus = fs.getFileStatus(dfs2);
FileStatus files[] = fs.listStatus(dfs3);
for(FileStatus file:files){
System.out.println(file.getPath());
}
BlockLocation[] blkLocations=fs.getFileBlockLocations(filestatus, 0, filestatus.getLen());
for(int i=0;i<blkLocations.length;i++){
String[] hosts = blkLocations[i].getHosts();
System.out.print("block_"+i+"_Location:"+hosts[i]);
}
long accessTime=filestatus.getAccessTime();
System.out.println("accessTime:"+accessTime);
long modificationTime =filestatus.getModificationTime();
System.out.println("modificationTime:"+modificationTime);
long blockSize =filestatus.getBlockSize();
System.out.println("blockSize:"+blockSize);
long len =filestatus.getLen();
System.out.println("len:"+len);
String group =filestatus.getGroup();
System.out.println("group:"+group);
String owner=filestatus.getOwner();
System.out.println("owner:"+owner);
fs.close();
}
}问题解决
(1)依赖包问题
编写程序需要相应的jar包,可以在Hadoop文件夹share中找到相应jar包进行导入
[root@slave1 hadoop-2.8.5]# ls share/hadoop/
common hdfs httpfs kms mapreduce tools yarn
[root@slave1 hadoop-2.8.5]#(2)程序运行问题
这里需要注意一下,Hadoop是部署在Linux集群上的,这里使用的是在Windows客户端通过编程由API来操作Hadoop集群中的HDFS。
在Widnows客户端直接编程操作API运行是会抛出异常的比如:
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems服务器Hadoop版本:
[root@master sbin]# hadoop version
Hadoop 2.8.5
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8
Compiled by jdu on 2018-09-10T03:32Z
Compiled with protoc 2.5.0
From source with checksum 9942ca5c745417c14e318835f420733
This command was run using /root/HadoopEnv/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar
[root@master sbin]#解决方案:
针对上面的情况,Windows本地不需要安装hadoop,但是需要配置%HADOOP_HOME%变量。
根据自己服务器版本,下载相应的winutils
winutils介绍:适用于Hadoop版本的Windows二进制文件,这些是直接从用于创建官方ASF版本的相同git提交构建的; 它们被检出并构建在Windows VM上,该VM专用于在Windows上测试Hadoop / YARN应用程序。
下载地址:不同版本 winutils
由于我的服务器Hadoop版本是2.8.5,但是下载版本里面和它相近的只有2.8.3,不过问题不大,他们之间会兼容的。下载好之后在Windows上设置环境变量,将环境变量%HADOOP_HOME%设置为指向包含WINUTILS.EXE的BIN目录上方的目录。
D:\hadoop-2.8.3关闭idea,重新用idea打开项目,启动项目,异常消失。
程序运行
download: from/HdfsFile/fe.txt to C:/Users/Qftm/Desktop
copy from: C:/Users/Qftm/Desktop/hdfs to /javaapi
hdfs://master:9000/javaapi/hdfs/MysqlLoadFile.txt
hdfs://master:9000/javaapi/hdfs/file.txt
block_0_Location:slave1accessTime:1591580862446
modificationTime:1591580862467
blockSize:134217728
len:622
group:supergroup
owner:root
Process finished with exit code 0从结果中可以看到Windows客户端上编写的程序正常执行了,然后去服务器上查看相应的HDFS
- 查看在HDFS下创建的文件夹与文件
[root@master sbin]# hdfs dfs -ls /HdfsFile
Found 1 items
-rw-r--r-- 3 root supergroup 0 2020-06-08 09:47 /HdfsFile/fe.txt
[root@master sbin]#- 查看从服务端下载到客户端的文件
RunResult:
download: from/HdfsFile/fe.txt to C:/Users/Qftm/Desktopλ Qftm >>>: stat fe.txt
File: fe.txt
Size: 0 Blocks: 0 IO Block: 65536 regular empty file
Device: 88a10a55h/2292255317d Inode: 16607023626061749 Links: 1
Access: (0644/-rw-r--r--) Uid: (197609/ Qftm) Gid: (197121/ UNKNOWN)
Access: 2020-06-08 09:47:41.928150400 +0800
Modify: 2020-06-08 09:47:41.928150400 +0800
Change: 2020-06-08 09:47:41.928150400 +0800
Birth: 2020-06-08 09:41:11.380997100 +0800- 查看从客户端上传到服务端的文件
RunResult:
copy from: C:/Users/Qftm/Desktop/hdfs to /javaapi[root@master sbin]# hdfs dfs -ls -R /javaapi
drwxr-xr-x - root supergroup 0 2020-06-08 09:47 /javaapi/hdfs
-rw-r--r-- 3 root supergroup 622 2020-06-08 09:47 /javaapi/hdfs/MysqlLoadFile.txt
-rw-r--r-- 3 root supergroup 5 2020-06-08 09:47 /javaapi/hdfs/file.txt
[root@master sbin]#查看客户端从服务端读取的上传文件信息
RunResult:
hdfs://master:9000/javaapi/hdfs/MysqlLoadFile.txt
hdfs://master:9000/javaapi/hdfs/file.txt
block_0_Location:slave1accessTime:1591580862446
modificationTime:1591580862467
blockSize:134217728
len:622
group:supergroup
owner:rootMapReduce 简单编程
编程一
对社交网站用户访问日志数据进行分析,统计用户在2016年每个自然日的总访问次数并输出。
- 用户访问数据格式
lucy 2016-01-01
lucy 2016-01-01
aa 2016-01-01
aa 2016-01-02
aa 2016-01-02
aa 2016-01-03
dd 2016-02-01
ee 2016-02-01
ff 2016-12-31
mm 2016-12-3(1)统计用户在2016年每个自然日的总访问次数并输出
- 程序编写
countmapper.java
package com.mapreduce.api;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class countmapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException{
String valueString = value.toString();
String str = valueString.split(" ")[0];
context.write(new Text(str),new LongWritable(1));
}
}
countreducer.java
package com.mapreduce.api;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class countreducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> value, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException{
Iterator<LongWritable> it = value.iterator();
long sum = 0;
while (it.hasNext()){
sum += it.next().get();
}
context.write(key, new LongWritable(sum));
}
}test.java
package com.mapreduce.api;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class test {
public static void main(String[] args) throws Exception{
Job job = new Job();
job.setJarByClass(test.class);
job.setMapperClass(countmapper.class);
job.setReducerClass(countreducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("/root/HadoopEnv/test/input/input1.txt"));
FileOutputFormat.setOutputPath(job, new Path("/root/HadoopEnv/test/output/output1"));
job.waitForCompletion(true);
System.out.println("finished!!!!!");
}
}- 运行结果
[root@master test]# cat output/output1/*
aa 4
dd 1
ee 1
ff 1
lucy 2
mm 1
[root@master test]# (2)在上一步的结果中按访问次数对输出结果进行排序并输出排序后的用户每日总访问次数情况。
- 编程思路
将上一步统计用户在2016年每个自然日的总访问次数的输出结果作为此题的mapper输入,将输入的key值和value值分别作为mapper输出时的value值和key值,然后在mapper到reducer端会自动按key值得大小排序,作为reducer的输入,之后在reducer输出端将key值和value值调换。
- 程序编写
sort.java
package com.mapreduce.api;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class sort{
public static class UserCountMapper extends Mapper<LongWritable,Text,IntWritable,Text>{
@Override
protected void map(LongWritable key,Text value,
Mapper<LongWritable,Text,IntWritable,Text>.Context context)
throws IOException,InterruptedException{
String[] ValueString=value.toString().split(" ");
int i=Integer.parseInt(ValueString[1]);
String str=ValueString[0];
context.write(new IntWritable(i), new Text(str));
}
}
public static class UserCountReducer extends Reducer<IntWritable,Text,Text,IntWritable>{
@Override
protected void reduce(IntWritable key, Iterable<Text> values,
Reducer<IntWritable,Text,Text,IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String val;
for(Text value:values){
val=value.toString();
context.write(new Text(val),key);
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
job.setJobName("job");
job.setJarByClass(sort.class);
job.setMapperClass(UserCountMapper.class);
job.setReducerClass(UserCountReducer.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("/root/HadoopEnv/test/output/output1"));
FileOutputFormat.setOutputPath(job, new Path("/root/HadoopEnv/test/output/output2"));
job.waitForCompletion(true);
}
}- 运行结果
[root@master test]# cat output/output2/*
mm 1
ff 1
ee 1
dd 1
lucy 2
aa 4
[root@master test]#编程二
基于MapReduce分析多年来气象数据最低温度和年气象数据平均温度。
- 数据格式
0067011990999991950051507004888888889999999N9+00001+9999999999999999999999
0067011990999991949051512004888888889999999N9+00221+9999999999999999999999
0067011990999991950050324004888888889999999N9+00331+9999999999999999999999
0067011990999991950050580004888888889999999N9-00111+9999999999999999999999数据说明:
第15-19个字符是year
第45-50位是温度表示,+表示零上,—表示零下,且温度的值不能是9999,9999表示异常数据
第50位值只能是0、1、4、5、9几个数字。- 编程思路
把采集的气象数据温度以日志的方式保存到指定的位置,该位置可以是本地,也可以是hdfs分布式系统上,本题我保存在本地上,然后利用hadoop计算数据对该日志文件进行处理,主要分两个阶段:mapper阶段和reducer阶段,mapper阶段主要是对日志文件进行按行读取并进行字符串截取,reducer阶段对mapper阶段传过来的数据进行大小比较,最终获取每一年中的最高温度。
(1)求平均温度
- 程序编写
AvgTemperatureMapper.java
package com.mapreduce.api1;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class AvgTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
protected void map (LongWritable key, Text value , Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();//读取一条记录
String year = line.substring(15, 19);//获取温度数
System.out.println("year=="+year);
int airTemperature;
if (line.charAt(45) == '+') { //判断温度正负
airTemperature = Integer.parseInt(line.substring(46, 50));
}else {
airTemperature = Integer.parseInt(line.substring(45, 50));
}
String quality = line.substring(50, 51);
System.out.println("quality:" + quality);
// 判断温度是否异常
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}AvgTemperatureReducer.java
package com.mapreduce.api1;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class AvgTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int avgValue = 0;
int count = 0;
int sum = 0;
for(IntWritable value: values){
sum+=value.get();
count++;
}
avgValue = sum/count;
context.write(key, new IntWritable(avgValue));
}
}AvgTemperature.java
package com.mapreduce.api1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class AvgTemperature {
public static void main(String[] args) throws Exception {
//获取作业对象
Job job = Job.getInstance(new Configuration());
//设置主类
job.setJarByClass(AvgTemperature.class);
//设置job参数
job.setMapperClass(AvgTemperatureMapper.class);
job.setReducerClass(AvgTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置job输入输出
FileInputFormat.addInputPath(job, new Path("/root/HadoopEnv/test/input/source.txt"));
FileOutputFormat.setOutputPath(job, new Path("/root/HadoopEnv/test/output/output3"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}- 运行结果
[root@master test]# cat output/output3/*
1949 22
1950 7
[root@master test]#(2)求最低温度
- 程序编写
MinTemperatureMapper.java
package com.mapreduce.api1;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MinTemperatureMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final int MISSING = 9999;
@Override
protected void map (LongWritable key, Text value , Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();//读取一条记录
String year = line.substring(15, 19);//获取温度数
System.out.println("year=="+year);
int airTemperature;
if (line.charAt(45) == '+') { //判断温度正负
airTemperature = Integer.parseInt(line.substring(46, 50));
}else {
airTemperature = Integer.parseInt(line.substring(45, 50));
}
String quality = line.substring(50, 51);
System.out.println("quality:" + quality);
// 判断温度是否异常
if (airTemperature != MISSING && quality.matches("[01459]")) {
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}MinTemperatureReducer.java
package com.mapreduce.api1;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MinTemperatureReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
//把Integer.Max_VALUE作为minValue的初始值
int minValue = Integer.MAX_VALUE;
//循环取出最大值
for(IntWritable value: values){
minValue = Math.min(minValue, value.get());
}
context.write(key, new IntWritable(minValue));
}
}MinTemperature.java
package com.mapreduce.api1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MinTemperature {
public static void main(String[] args) throws Exception {
//获取作业对象
Job job = Job.getInstance(new Configuration());
//设置主类
job.setJarByClass(MinTemperature.class);
//设置job参数
job.setMapperClass(MinTemperatureMapper.class);
job.setReducerClass(MinTemperatureReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置job输入输出
FileInputFormat.addInputPath(job, new Path("/root/HadoopEnv/test/input/source.txt"));
FileOutputFormat.setOutputPath(job, new Path("/root/HadoopEnv/test/output/output4"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}- 运行结果
[root@master test]# cat output/output4/*
1949 22
1950 -11
[root@master test]#编程三
基于MapReduce进行专利文献分析
- 数据格式
数据来源于美国专利文献数据中的数据文件:
cite75-99.txt:专利文献引用关系数据文件,数据集格式:
3858241,956203
3858241,1324234
3858241,3398406
3858241,3557384
3858241,3634889
3858242,1515701
3858242,3319261
3858242,3668705
3858242,3707004
3858243,2949611
3858243,3146465
3858243,3156927
3858243,3221341
3858242,3398406
3858243,3398406文件中为多行记录,每条记录由两个专利号构成,表示前一个专利引用后一个专利。
apat63_99.txt:专利描述文件,描述每个专利的相关信息,数据集格式:
3070801,1963,1096,,"BE","",,1,,269,6,69,,1,,0,,,,,,,
3070802,1963,1096,,"US","TX",,1,,2,6,63,,0,,,,,,,,,
3070803,1963,1096,,"US","IL",,1,,2,6,63,,9,,0.3704,,,,,,,
3070804,1963,1096,,"US","OH",,1,,2,6,63,,3,,0.6667,,,,,,,
3070805,1963,1096,,"US","CA",,1,,2,6,63,,1,,0,,,,,,,
3070806,1964,1096,,"US","PA",,1,,2,6,63,,0,,,,,,,,,
3070807,1964,1096,,"US","OH",,1,,623,3,39,,3,,0.4444,,,,,,,
3070808,1964,1096,,"US","IA",,1,,623,3,39,,4,,0.375,,,,,,,
3070809,1964,1096,,"US","AZ",,1,,4,6,65,,0,,,,,,,,,
3070810,1965,1096,,"US","IL",,1,,4,6,65,,3,,0.4444,,,,,,,
3070811,1965,1096,,"US","CA",,1,,4,6,65,,8,,0,,,,,,,
3070812,1965,1096,,"US","LA",,1,,4,6,65,,3,,0.4444,,,,,,,
3070813,1965,1096,,"US","NY",,1,,5,6,65,,2,,0,,,,,,,(1)构建专利被引用列表
- 编程思路
将一行数据的前一个专利号作为value值,后一个专利号作为key值
- 程序编写
Patentlist.java
package com.mapreduce.api2;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 构建专利引用列表,输入专利引用关系的关系对(patentNo1,patentNo2)
* 文件,输出每个专利号的所引用的文件,以逗号相隔。
*/
public class Patentlist {
public static class PatentCitationMapper extends Mapper<LongWritable,Text,Text,Text>{
/**
* 输入键位行偏移,值为“专利号1,专利号2”
*/
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] citation = value.toString().split(",");
/*for(int i=0;i<citation.length;i++){
System.out.println(citation[0]+" "+citation[1]);
}*/
context.write(new Text(citation[1]), new Text(citation[0]));
}
}
public static class PatentCitationReducer extends Reducer<Text,Text,Text,Text>{
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder csv = new StringBuilder(""); //设置可变字符串缓冲区
for (Text val:values) { //遍历value集合
if (csv.length() > 0) {
csv.append(",");
}
csv.append(val.toString());
}
context.write(key, new Text(csv.toString()));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException{
Job patentCitationJob = new Job();
patentCitationJob.setJobName("patentCitationJob");
patentCitationJob.setJarByClass(Patentlist.class);
patentCitationJob.setMapperClass(PatentCitationMapper.class);
patentCitationJob.setMapOutputKeyClass(Text.class);
patentCitationJob.setMapOutputValueClass(Text.class);
patentCitationJob.setReducerClass(PatentCitationReducer.class);
patentCitationJob.setOutputKeyClass(Text.class);
patentCitationJob.setOutputValueClass(Text.class);
patentCitationJob.setInputFormatClass(TextInputFormat.class);
patentCitationJob.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(patentCitationJob, new Path("/root/HadoopEnv/test/input/patentin1.txt"));
FileOutputFormat.setOutputPath(patentCitationJob, new Path("/root/HadoopEnv/test/output/patentout1"));
patentCitationJob.waitForCompletion(true);
System.out.println("finished!");
}
}- 运行结果
[root@master test]# cat output/patentout1/*
1324234 3858241
1515701 3858242
2949611 3858243
3146465 3858243
3156927 3858243
3221341 3858243
3319261 3858242
3398406 3858241,3858242,3858243
3557384 3858241
3634889 3858241
3668705 3858242
3707004 3858242
956203 3858241
[root@master test]# (2)专利被引用次数统计
- 程序编写
PatentCount.java
package com.mapreduce.api2;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 专利被引用次数统计
*/
public class PatentCount {
public static class PatentCitationMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
private IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 输入key: 行偏移值;value: “citing专利号, cited专利号” 数据对
String[] citation = value.toString().split(",");
// 输出key: cited 专利号;value: 1
context.write(new Text(citation[1]), one);
}
}
public static class ReduceClass extends Reducer<Text, IntWritable, Text, IntWritable>
{
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable val : values){
count += val.get();
}
// 输出key: 被引专利号;value: 被引次数
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException{
Job citationCountJob = new Job();
citationCountJob.setJobName("citationCountJob");
citationCountJob.setJarByClass(PatentCount.class);
citationCountJob.setMapperClass(PatentCitationMapper.class);
citationCountJob.setMapOutputKeyClass(Text.class);
citationCountJob.setMapOutputValueClass(IntWritable.class);
citationCountJob.setReducerClass(ReduceClass.class);
citationCountJob.setOutputKeyClass(Text.class);
citationCountJob.setOutputValueClass(IntWritable.class);
citationCountJob.setInputFormatClass(TextInputFormat.class);
citationCountJob.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(citationCountJob, new Path("/root/HadoopEnv/test/input/patentin1.txt"));
FileOutputFormat.setOutputPath(citationCountJob, new Path("/root/HadoopEnv/test/output/patentcount1"));
citationCountJob.waitForCompletion(true);
System.out.println("finished!");
}
}- 运行结果
[root@master test]# cat output/patentcount1/*
1324234 1
1515701 1
2949611 1
3146465 1
3156927 1
3221341 1
3319261 1
3398406 3
3557384 1
3634889 1
3668705 1
3707004 1
956203 1
[root@master test]#(3)专利被引用次数分布统计,例如被引用次数为1的文献有多少个
将第二步中的输出结果作为这一步的输入
- 程序编写
CitationCountDistribution.java
package com.mapreduce.api2;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 专利被引用次数分布统计,输入文件为专利引用次数统计的输出结果
* 扫描文件忽略专利号,仅仅考虑被引用的次数,统计每一个次数分别
* 有多少次出现。
*/
public class CitationCountDistribution {
public static class MapClass extends Mapper<LongWritable, Text, IntWritable, IntWritable> {
private IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] citation = value.toString().split(" ");
IntWritable citationCount = new IntWritable(Integer.parseInt(citation[1]));
context.write (citationCount, one);
}
}
public static class ReduceClass extends Reducer<IntWritable,IntWritable,IntWritable,IntWritable>{
public void reduce(IntWritable key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable val : values){
count += val.get();
}
// 输出key: 被引次数;value: 总出现次数
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException{
Job citationCountDistributionJob = new Job();
citationCountDistributionJob.setJobName("citationCountDistributionJob");
citationCountDistributionJob.setJarByClass(CitationCountDistribution.class);
citationCountDistributionJob.setMapperClass(MapClass.class);
citationCountDistributionJob.setMapOutputKeyClass(IntWritable.class);
citationCountDistributionJob.setMapOutputValueClass(IntWritable.class);
citationCountDistributionJob.setReducerClass(ReduceClass.class);
citationCountDistributionJob.setOutputKeyClass(IntWritable.class);
citationCountDistributionJob.setOutputValueClass(IntWritable.class);
citationCountDistributionJob.setInputFormatClass(TextInputFormat.class);
citationCountDistributionJob.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(citationCountDistributionJob, new Path("/root/HadoopEnv/test/output/patentcount1"));
FileOutputFormat.setOutputPath(citationCountDistributionJob, new Path("/root/HadoopEnv/test/output/patentcount2"));
citationCountDistributionJob.waitForCompletion(true);
System.out.println("finished!");
}
}- 运行结果
[root@master test]# cat output/patentcount2/*
1 12
3 1
[root@master test]#(4)分别按照年份和国家统计专利数
colNo为4,表示按国家统计专利数,为1,表示按照年份统计专利数。
- 程序编写
CitationBy.java
package com.mapreduce.api2;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* 按照特定属性统计,例如按照年份统计每一年专利数目
* 或者按照国家统计每个国家的专利数目
*/
public class CitationBy {
public static class MapClass extends Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private int colNo;//属性的列号,决定按照哪个属性值进行统计,年份1,国家4。
@Override
protected void setup(Context context) throws IOException,InterruptedException{
colNo = context.getConfiguration().getInt("col", 4);//默认按照年份统计
}
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] cols = value.toString().split(","); // value:读入的一行专利描述数据记录
String col_data = cols[colNo];
context.write (new Text(col_data), one);
}
}
public static class ReduceClass extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable val : values){
count += val.get();
}
// 输出key: 年份或国家;value: 总的专利数
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException{
Job citationByJob = new Job();
citationByJob.setJobName("citationByJob");
citationByJob.setJarByClass(CitationBy.class);
citationByJob.setMapperClass(MapClass.class);
citationByJob.setMapOutputKeyClass(Text.class);
citationByJob.setMapOutputValueClass(IntWritable.class);
citationByJob.setReducerClass(ReduceClass.class);
citationByJob.setOutputKeyClass(Text.class);
citationByJob.setOutputValueClass(IntWritable.class);
citationByJob.setInputFormatClass(TextInputFormat.class);
citationByJob.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(citationByJob, new Path("/root/HadoopEnv/test/input/patentin2.txt"));
FileOutputFormat.setOutputPath(citationByJob, new Path("/root/HadoopEnv/test/output/patentcount3"));
citationByJob.getConfiguration().setInt("col", 4);
citationByJob.waitForCompletion(true);
System.out.println("finished!");
}
}- 运行结果
[root@master test]# cat output/patentcount3/*
"BE" 1
"US" 12
[root@master test]# MapReduce 高级编程
编程一
对专利数据进行分析,编写MapReduce程序统计每年每个国家申请的专利数,并按如下形式输出统计结果:
年 国家:专利数;国家:专利数 。。。
年 国家:专利数- 数据格式
3070801,1963,1096,,"BE","",,1,,269,6,69,,1,,0,,,,,,,
3070802,1963,1096,,"US","TX",,1,,2,6,63,,0,,,,,,,,,
3070803,1963,1096,,"US","IL",,1,,2,6,63,,9,,0.3704,,,,,,,
3070804,1963,1096,,"US","OH",,1,,2,6,63,,3,,0.6667,,,,,,,
3070805,1963,1096,,"US","CA",,1,,2,6,63,,1,,0,,,,,,,
3070806,1964,1096,,"US","PA",,1,,2,6,63,,0,,,,,,,,,
3070807,1964,1096,,"US","OH",,1,,623,3,39,,3,,0.4444,,,,,,,
3070808,1964,1096,,"US","IA",,1,,623,3,39,,4,,0.375,,,,,,,
3070809,1964,1096,,"US","AZ",,1,,4,6,65,,0,,,,,,,,,
3070810,1965,1096,,"US","IL",,1,,4,6,65,,3,,0.4444,,,,,,,
3070811,1965,1096,,"US","CA",,1,,4,6,65,,8,,0,,,,,,,
3070812,1965,1096,,"US","LA",,1,,4,6,65,,3,,0.4444,,,,,,,
3070813,1965,1096,,"US","NY",,1,,5,6,65,,2,,0,,,,,,,- 程序编写
Patent.java
package com.mapreduce.api2;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
public class Patent {
public static class PatentMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String [] cols=value.toString().split(",");
String year=cols[1];//定义年份
String country=cols[4];//定义国家
//String yearcon=year+""+country;
Text yearcon=new Text();
yearcon.set(year+"#"+country);//将年份#国家整体放到yearcon里
context.write(yearcon,new LongWritable(1));
}
}
public static class SumCombiner extends Reducer<Text,LongWritable,Text,LongWritable>{
private LongWritable result=new LongWritable();
protected void reduce(Text key, Iterable<LongWritable> values,Context context)throws IOException, InterruptedException {
int sum=0;
for(LongWritable val:values){//同一个节点的专利数进行累加
sum+=val.get();
}
result.set(sum);
context.write(key,result);
}
}
public static class NewPartitioner extends HashPartitioner<Text,LongWritable>{
public int getPartition(Text key,LongWritable value,int numReduceTasks){
String year=new String();
year=key.toString().split("#")[0];//从key中分割出年份
//重新设置key(year),value值
return super.getPartition(new Text(year),value,numReduceTasks);
}
}
public static class PatentReducer extends Reducer<Text,LongWritable,Text,Text>{
private Text word1=new Text();
private Text word2=new Text();
String country=new String();
static Text CurrentYear=new Text(" ");//设置currentyear初始值为空
static List<String> postingList=new ArrayList<String>();//设置集合
public void reduce(Text key,Iterable<LongWritable> values,Context context) throws IOException,InterruptedException{
int sum=0;
word1.set(key.toString().split("#")[0]);//将key分割出的year赋给word1
country=key.toString().split("#")[1];//从key分割出country
for(LongWritable val:values){
sum+=val.get(); //将每个country对应的专利数进行累加
}
word2.set(country+":"+sum);//将(country:专利数)设置为word2
//判定currentyear与word1不相等且currentyear不为空条件成立,执行
if(!CurrentYear.equals(word1)&&!CurrentYear.equals(" ")){
StringBuilder out=new StringBuilder();//创建一个out缓存对象
//将同一年份不同国家的专利数间用“;”隔开
for(String p:postingList){
out.append(p);//将postinglist中内容放到out对象中
out.append(";"); //不同国家专利数间加“;”
}
if(out.length()>0){
out.deleteCharAt(out.length()-1);//去除多余的最后一个“;”
}
context.write(CurrentYear,new Text(out.toString()));
postingList=new ArrayList<String>();//将postinglist集合置空
}
CurrentYear=new Text(word1);//将word1赋给currentyear
postingList.add(word2.toString());//将word2内容加到postinglist集合
}
public void cleanup(Context context)throws IOException,InterruptedException{
StringBuilder out=new StringBuilder();
for(String p:postingList){
out.append(p);//将postinglist中内容放到out对象中
out.append(";"); //加“;”
}
if(out.length()>0){
out.deleteCharAt(out.length()-1);//去除多余的最后一个“;”
}
context.write(CurrentYear,new Text(out.toString()));
}
}
public static void main(String args[]) throws Exception{
Configuration conf=new Configuration();
Job job=new Job(conf,"patent");
job.setJarByClass(Patent.class);
job.setMapperClass(PatentMapper.class);
job.setCombinerClass(SumCombiner.class);
job.setReducerClass(PatentReducer.class);
job.setPartitionerClass(NewPartitioner.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job,new Path("/root/HadoopEnv/test/input/patentin2.txt"));
FileOutputFormat.setOutputPath(job,new Path("/root/HadoopEnv/test/output/patentcount4"));
System.exit(job.waitForCompletion(true)?0:1);
}
}
